Seja \(\mathbf{X_1,...,X_n}\) uma a.a. i.i.d. da distribuição \(Pois(\lambda)\) e \[
\hat{\lambda}=\hat{X}=\frac{1}{n}\sum_{i=1}^n X_i
\] Um intervalo de confiança para \(\lambda\) é dado por \[
IC(\lambda) = \left[\bar{X}-\frac{p_{n,\alpha}\hat{\sigma}}{\sqrt{n}};\bar{X}+\frac{p_{n,\alpha}\hat{\sigma}}{\sqrt{n}}\right],
\] em que \(\hat{\sigma}^2=\frac{1}{n-1}\sum_{i=1^n (X_i-\bar{X})^2}\) e \(p_{n,\alpha}\) pode ser escolhido como o \(1-\frac{\alpha}{2}\) quantil da \(t\) com \(n-1\) graus de liberdade. Escreva um código para calcular a estimativa de Monte Carlo para o coeficiente de confiança do intervalo de confiança acima. Para \(n=10\) e \(\alpha=5\%\), usando o valor \(p_{10,0.05}=2.262157\), estime o coeficiente de confiança para um rol de valores de \(\lambda\) (e.g.,0.025-1) e crie um plot dos resultados. Comente sobre os resultados obtidos.
Solução
Show the code
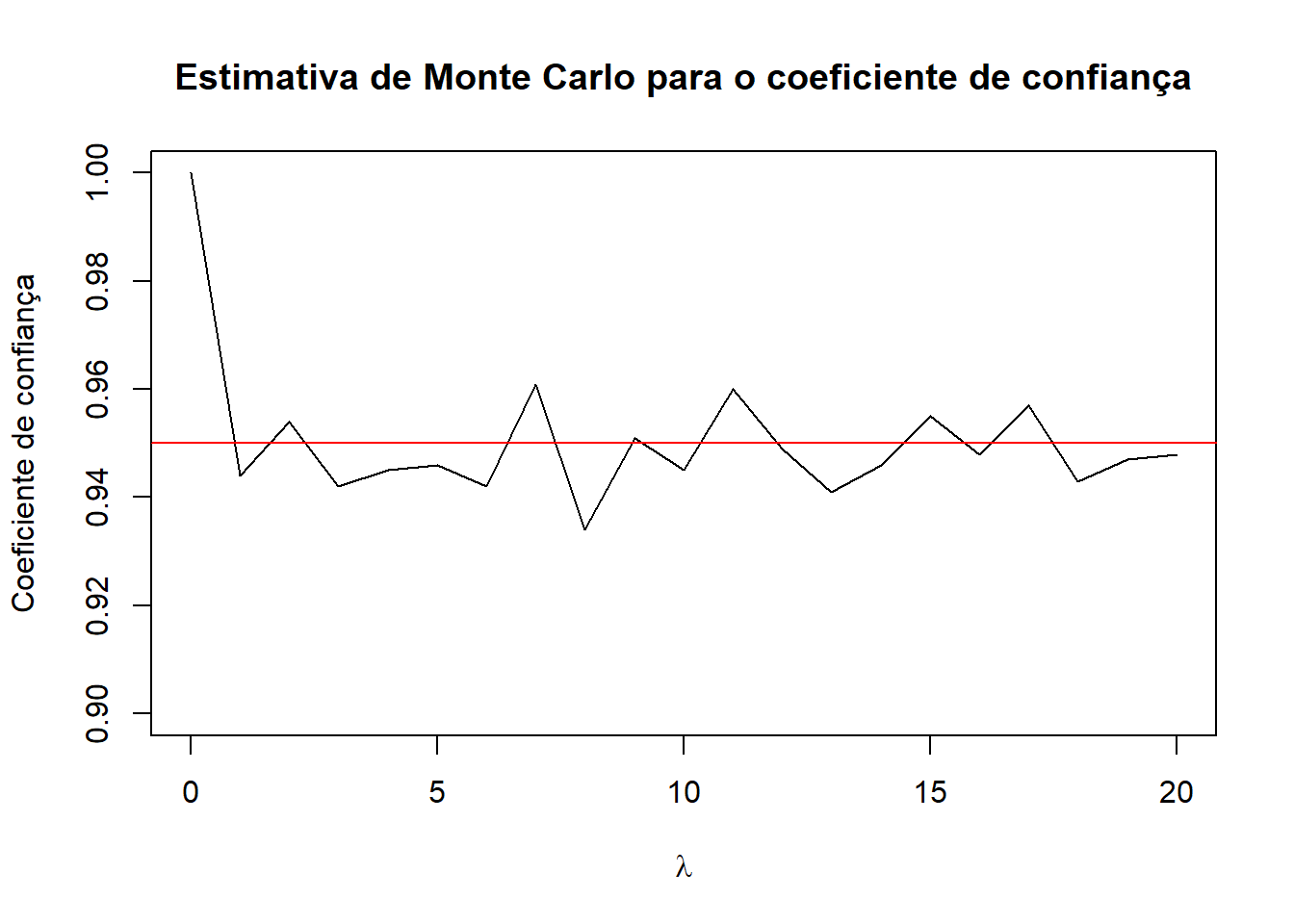
N =1000alpha = .05n =10p =2.262157lambda =seq(0,20,by=1)nlambda =length(lambda)cobertura <-numeric(nlambda)for (i in1:nlambda){ Lambda = lambda[i] capturado =0for (j in1:N){ x =rpois(n,Lambda) xbar =mean(x) sigma2 = (1/(n-1)) *sum((x-xbar)^2) ici = xbar - (p *sqrt(sigma2/n)) ics = xbar + (p *sqrt(sigma2/n))if (Lambda >= ici & Lambda <= ics){ capturado = capturado +1} } cobertura[i] = capturado/N}plot(lambda, cobertura, type ="l", ylim =c(0.9, 1), xlab =expression(lambda), ylab ="Coeficiente de confiança",main ="Estimativa de Monte Carlo para o coeficiente de confiança")abline(h =1- alpha, col ="red")
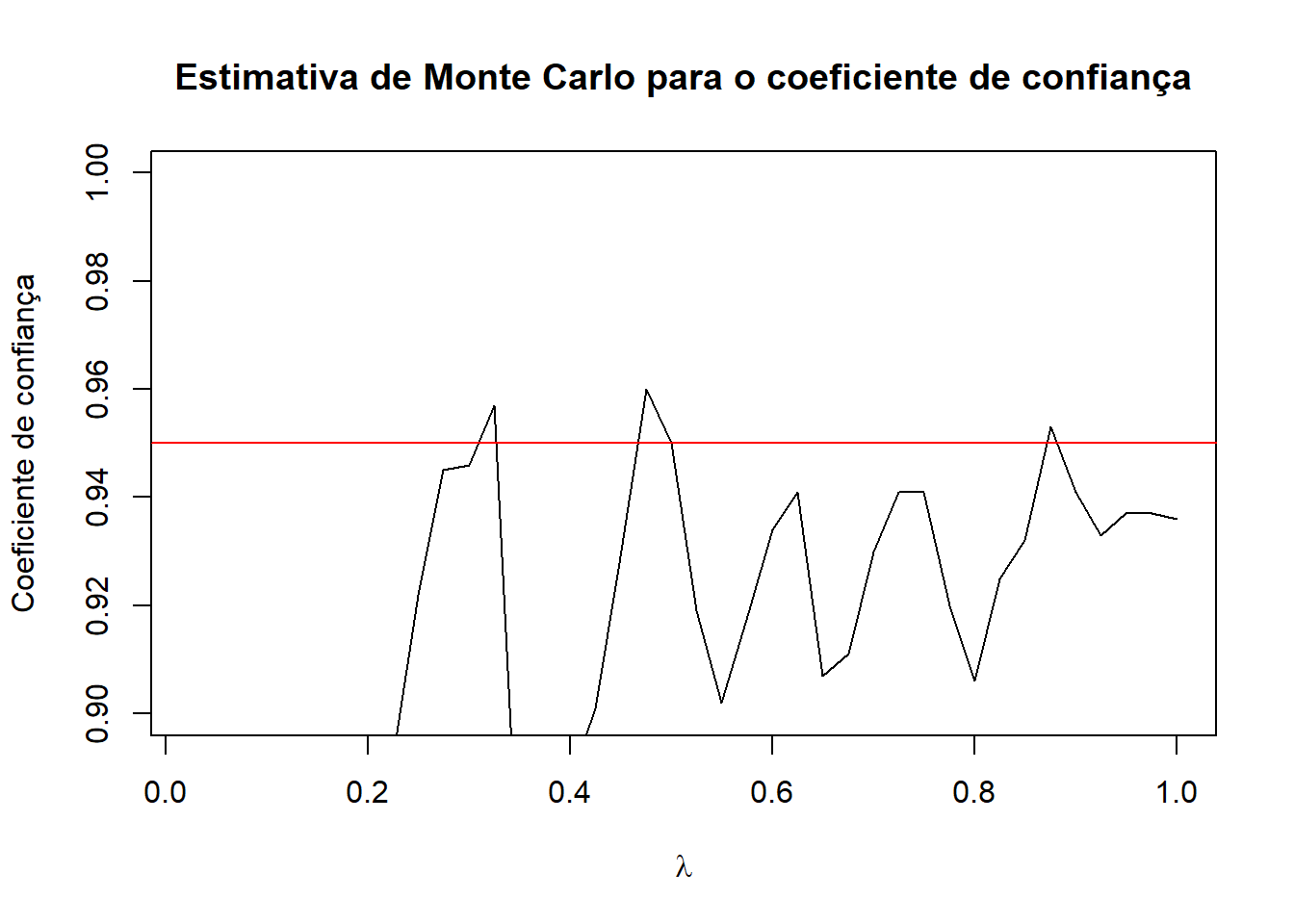
Notamos pelo gráfico que os intervalos contém o verdadeiro parâmetro empiricamente aproximadamente a quantidade teórica esperada de 95%, para valores de \(\lambda=\{1,2,3,...,20\}\). Este resultado, porém, difere para valores muito pequenos de \(\lambda\), onde a sensibilidade da estimativa empírica para \(n=10\) não é tão poderosa, como pode-se observar no gráfico a seguir, para valores de \(\lambda\) de 0,025 a 1, de 0,025 em 0,025:
Show the code
lambda =seq(0.025,1,by=0.025)nlambda =length(lambda)cobertura <-numeric(nlambda)for (i in1:nlambda){ Lambda = lambda[i] capturado =0for (j in1:N){ x =rpois(n,Lambda) xbar =mean(x) sigma2 = (1/(n-1)) *sum((x-xbar)^2) ici = xbar - (p *sqrt(sigma2/n)) ics = xbar + (p *sqrt(sigma2/n))if (Lambda >= ici & Lambda <= ics){ capturado = capturado +1} } cobertura[i] = capturado/N}plot(lambda, cobertura, type ="l", ylim =c(0.9, 1), xlab =expression(lambda), ylab ="Coeficiente de confiança",main ="Estimativa de Monte Carlo para o coeficiente de confiança")abline(h =1- alpha, col ="red")
Para este cenário, seria necessário aumentar o valor de \(n\).
Exercício 2
Considere o teste de comparação de médias \[
Hipótese:\begin{cases}
H_0:\mu_1=\mu_2=0, \\
H_1:\mu_1\neq\mu_2
\end{cases}
\] Estude o poder do teste para \(\alpha=0.05, n=m \in\{10,20,50,100,500\}\), e \(\sigma^2_1=\sigma^2_2=1\). Considere a normal contaminada sob \(H_1\),i.e., \[
\mathbf{X,Y \sim (1-\epsilon)N(\mu=0,\sigma^2=1)+\epsilon N(\mu=50,\sigma^2=1),0\leq\epsilon\leq1.}
\] Considerar o número de réplicar de Monte Carlo igual a 1000. Faça um plot da curva de potência em função de \(\epsilon\) para cada tamanho de amostra. Comente os resultados obtidos.
Solução
Show the code
alpha =0.05N =1000m =c(10, 20, 50, 100, 500)epsilon =seq(0, 1, by =0.05)rejeicao =matrix(0, nrow =length(m), ncol =length(epsilon))rownames(rejeicao) =paste0("n=", m)colnames(rejeicao) =paste0("e=", epsilon)for (i in1:length(m)) { n = m[i]for (j in1:length(epsilon)) { eps = epsilon[j] rejeicoes =0for (k in1:N) { x =rnorm(n, mean =0, sd =1) n_contaminados =round(eps * n) y =c(rnorm(n_contaminados, mean =50, sd =1),rnorm(n - n_contaminados, mean =0, sd =1)) teste =t.test(x, y)if (teste$p.value < alpha) { rejeicoes = rejeicoes +1 } } rejeicao[i, j] = rejeicoes / N }}
Show the code
knitr::kable(rejeicao)
e=0
e=0.05
e=0.1
e=0.15
e=0.2
e=0.25
e=0.3
e=0.35
e=0.4
e=0.45
e=0.5
e=0.55
e=0.6
e=0.65
e=0.7
e=0.75
e=0.8
e=0.85
e=0.9
e=0.95
e=1
n=10
0.038
0.049
0
0.000
0.000
0
0
0.999
0.999
0.999
1
1
1
1
1
1
1
1
1
1
1
n=20
0.048
0.000
0
0.001
0.868
1
1
1.000
1.000
1.000
1
1
1
1
1
1
1
1
1
1
1
n=50
0.050
0.000
1
1.000
1.000
1
1
1.000
1.000
1.000
1
1
1
1
1
1
1
1
1
1
1
n=100
0.036
0.991
1
1.000
1.000
1
1
1.000
1.000
1.000
1
1
1
1
1
1
1
1
1
1
1
n=500
0.053
1.000
1
1.000
1.000
1
1
1.000
1.000
1.000
1
1
1
1
1
1
1
1
1
1
1
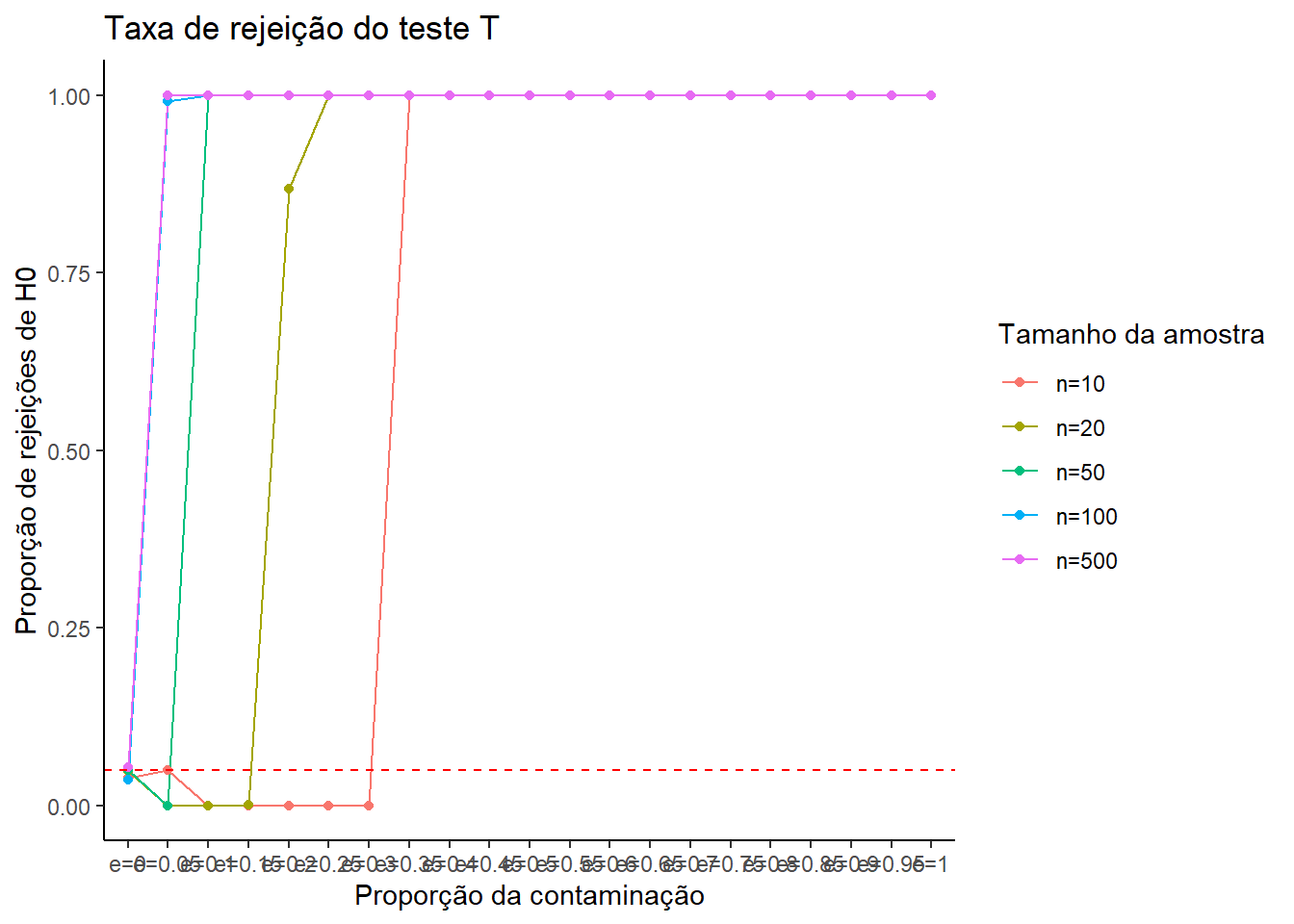
Pela Tabela acima, nota-se que já para pequenos valores de \(\epsilon\) e/ou maiores valores de \(n\), a maior parte dos testes irá rejeitar. Isto se dá pelo fato da contaminação ser bastante severa, em que ao adicionar uma pequena proporção de uma contaminação \(\sim N(50,1)\), o teste t irá rejeitar a igualdade de médias em relação à amostra gerada da distribuição \(N(0,1)\).
Esta evolução pode ser melhor observada pelo gráfico da curva de potência em função de \(\epsilon\) para cada tamanho de amostra:
Show the code
df =melt(rejeicao)colnames(df) =c("n","e","rejeicao")ggplot(df, aes(x = e, y = rejeicao, color =factor(n), group =factor(n))) +geom_line() +geom_point() +geom_hline(yintercept = alpha, linetype ="dashed", color ="red") +labs(title ="Taxa de rejeição do teste T",x ="Proporção da contaminação",y ="Proporção de rejeições de H0",color ="Tamanho da amostra" ) +theme_classic()