Classificação salarial via algorítmos de Machine Learning
Tópicos 2 — Modelagem com apoio computacional
Covariáveis numéricas


| age | education_num | capital_gain | capital_loss | hours_per_week | |
|---|---|---|---|---|---|
| Min. :17.00 | Min. : 1.00 | Min. : 0 | Min. : 0.0 | Min. : 1.00 | |
| 1st Qu.:28.00 | 1st Qu.: 9.00 | 1st Qu.: 0 | 1st Qu.: 0.0 | 1st Qu.:40.00 | |
| Median :37.00 | Median :10.00 | Median : 0 | Median : 0.0 | Median :40.00 | |
| Mean :38.58 | Mean :10.08 | Mean : 1078 | Mean : 87.3 | Mean :40.44 | |
| 3rd Qu.:48.00 | 3rd Qu.:12.00 | 3rd Qu.: 0 | 3rd Qu.: 0.0 | 3rd Qu.:45.00 | |
| Max. :90.00 | Max. :16.00 | Max. :99999 | Max. :4356.0 | Max. :99.00 |
Covariáveis categóricas

Importâncias para o modelo logístico
Podemos observar as covariáveis de maior importância para este modelo, assim como sua matriz de confusão

Modelo 2: Regressão Lasso
Como observado na receita do modelo, existem 38 covariáveis nesta modelagem. Diversas abordagens podem ser utilizadas para selecionar as covariáveis de maior importância, sendo uma dessas a regressão lasso, que penaliza coeficientes e torna-os 0 em caso de insignificância.
Este é um modelo que contém um hiperparâmetro, portanto iremos ajustar um grid para escolher o melhor possível.
lasso_spec <- logistic_reg(penalty = tune(),
mixture = 1) %>%
set_engine("glmnet")
lasso_wf <- workflow() %>%
add_recipe(recipe) %>%
add_model(lasso_spec)
grid <- grid_regular(penalty(),
levels = 100)
plan(multisession)
set.seed(150167636)
lasso_res <- lasso_wf %>%
tune_grid(resamples = cv_folds,
grid = grid,
metrics = metric_set(roc_auc))
Podemos ver que um menor valor de penalização é benéfico ao modelo, visto a importância relativa das covariáveis serem altas neste caso
Importâncias para o modelo Lasso
Podemos observar as covariáveis de maior importância para este modelo, assim como sua matriz de confusão

Ajuste do XGBoost
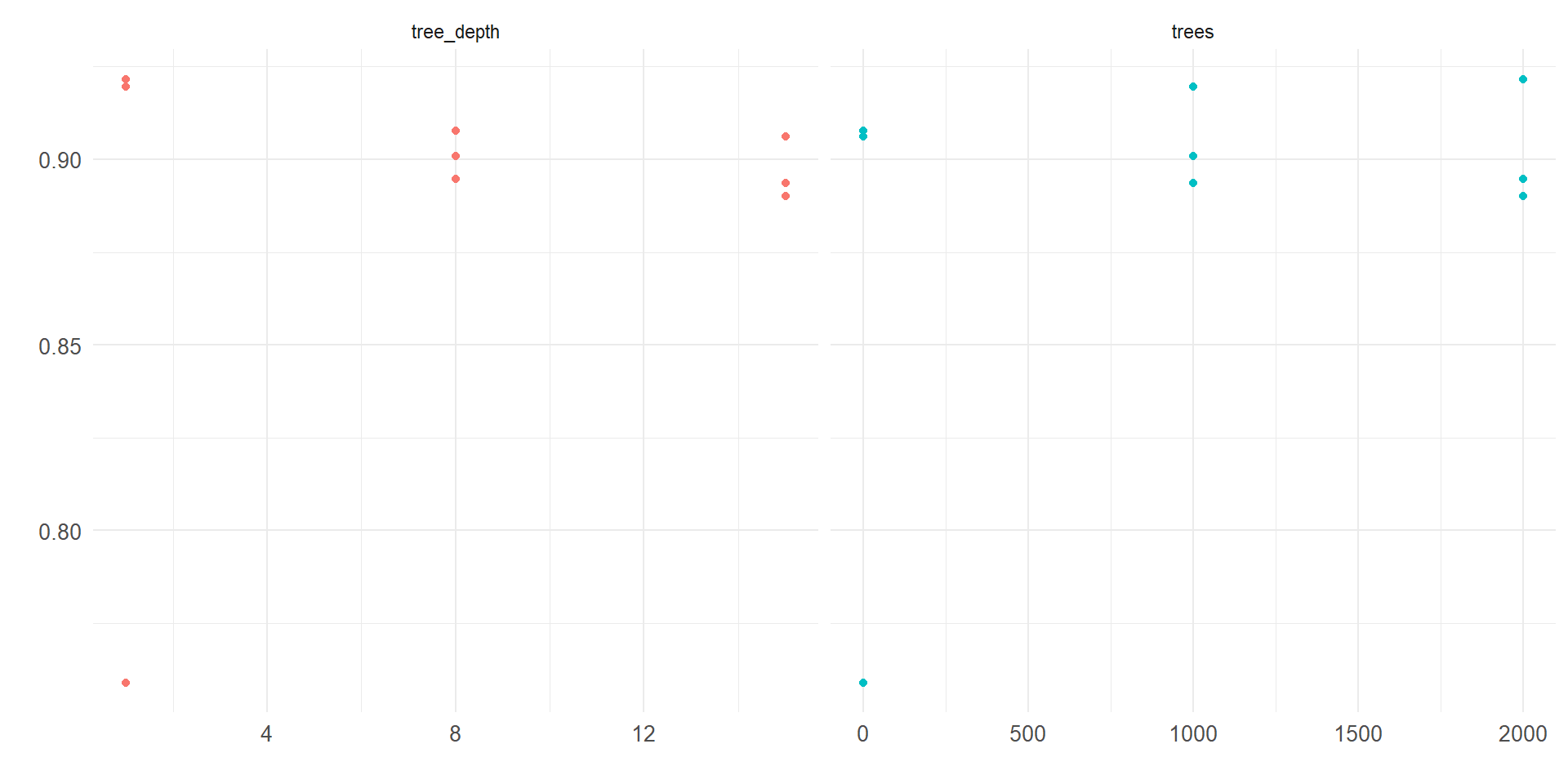
Também iremos realizar o fine tuning de alguns hiperparâmetros deste modelo, no caso o número de árvores e a profundidade destas, afim de obter o melhor modelo.
model = boost_tree(mode = "classification",
trees = tune(),
tree_depth = tune()
) %>%
set_engine("xgboost")
wf = workflow() %>%
add_recipe(recipe) %>%
add_model(model)
grid = wf %>%
extract_parameter_set_dials() %>%
grid_regular(levels = 3)
plan(multisession)
set.seed(150167636)
tune_res = tune_grid(
wf,
resamples = cv_folds,
grid = grid,
metrics = metric_set(accuracy, roc_auc, sens,spec)
)
# A tibble: 1 × 3
trees tree_depth .config
<int> <int> <chr>
1 2000 1 Preprocessor1_Model3Vemos que a melhor combinação de hiperparâmetros encontrada é utilizando 2000 árvores de tamanho 1
Importâncias para o XGBoost
Podemos observar as covariáveis de maior importância para este modelo, assim como sua matriz de confusão

