graph TD
A[Recebimento] --> B{Triagem Inicial};
B --> C[Distribuição];
B --> T1[...];
T1 --> T2[Busca por similaridade com \n outros processos do acervo];
T2 --> T3[...];
T3 --> B;
C --> D[...];
Similaridade de Processos Judiciários Utilizando Processamento de Linguagem Natural
Conjunto de dados
Os dados utilizados para esta análise são as petições iniciais dos processos de controle concentrado. Este é o primeiro documento que chega no Tribunal tratando de um processo.
Desta forma, o desafio é encontrar similaridades entre processos na sua fase inicial de tramitação, tal que esta ferramenta seja desbravadora na busca de similaridades antes de outros encaminhamentos internos no Tribunal.
As petições iniciais são um dado público, e podem ser obtidas no Portal do STF.
Para realizar a busca por similaridades, necessitamos fixar um processo, que chamaremos de paradigma.
Os processos paradigmas selecionados foram aqueles que tiveram pauta ou decisão conjunta pelo Tribunal com outros processos.
Desta forma, buscou-se encontrar técnicas que apontassem a similaridade desses processos já em suas petições iniciais.

Referencial teórico — Vetorização
Por se tratar de um dado textual, é necessário aplicar técnicas de vetorização ao texto.
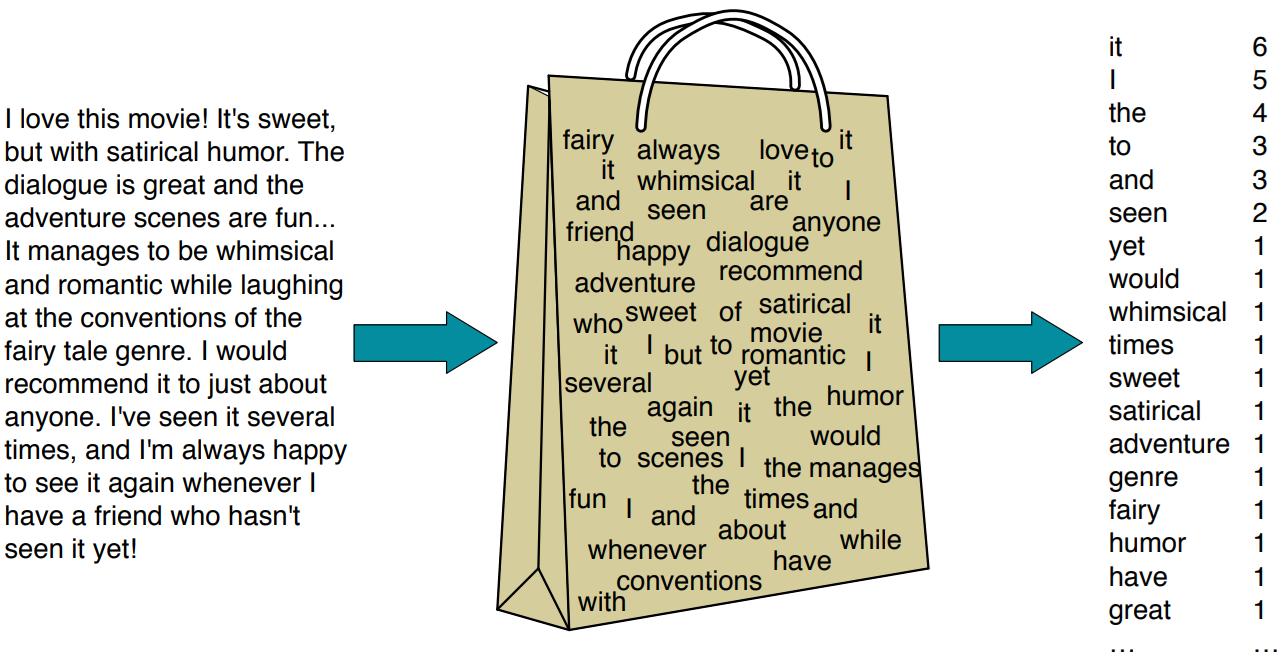
Esta é uma das formas mais simples de vetorizar um texto. Iremos simplesmente tabelar a frequência de utilização de cada um dos termos presentes no texto.
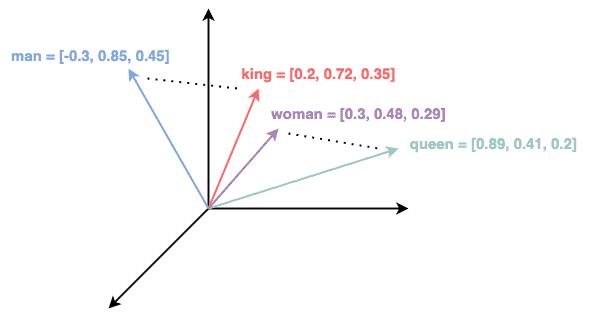
Esta é uma das formas mais sofisticadas para vetorização de texto. Nela, iremos obter o vetor numérico que representa o texto pelo treinamento de uma rede neural. Os parâmetros deste modelo são atualizados buscando prever a próxima palavra dado o seu contexto e dado um vetor de palavras que formam coletivamente o texto (Freitas et al. ,2024).
Referencial teórico — Métricas de similaridade
Para comparar os vetores criados, necessitamos de métricas de distância estatística
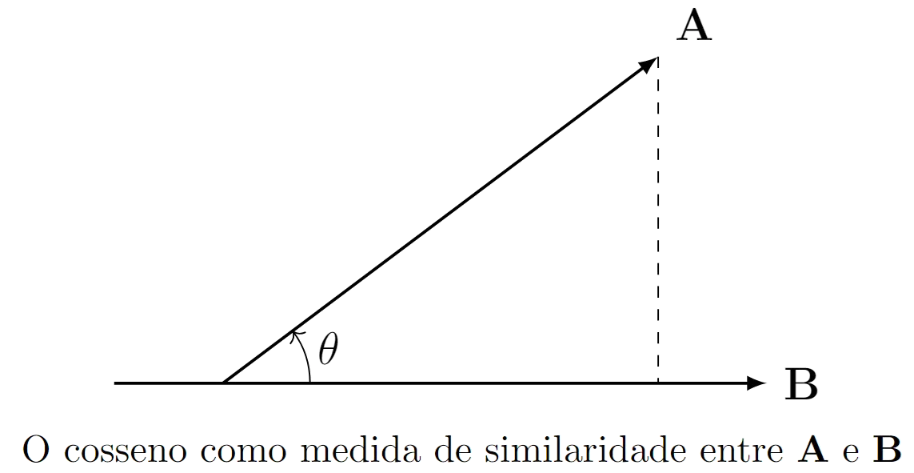
Pela Lei dos cossenos:
\[\begin{equation} \mathbf{A} \cdot \mathbf{B} = | \mathbf{A}|| \mathbf{B}|\cos\theta. \end{equation}\]
Podemos utilizar, para avaliar o grau de similaridade entre os vetores \(\mathbf{A}\) e \(\mathbf{B}\), a correlação entre eles. E para quantificar esta correlação, podemos utilizar o cosseno do ângulo entre estes vetores, tal que:
\[\begin{equation}\text{sim}(\mathbf{A,B}) = \cos\theta = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}|| \mathbf{B}|}. \end{equation}\]
Esta é possivelmente a métrica mais utilizada no paradigma de NLP.
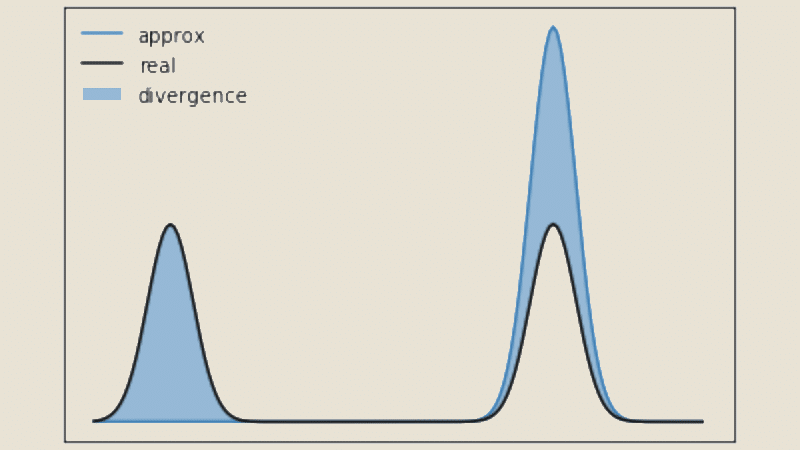
Uma outra métrica popular na área de Machine Learning, podemos calcular o complementar da divergência de Jensen-Shannon definida por:
\[\begin{equation} JSD(P||Q) = \\ \frac{1}{2}(KL(P||R)+KL(Q||R)), \end{equation}\]
como sendo uma medida de similaridade entre duas distribuições de probabilidade. No caso, tomamos os vetores como distribuições de probabilidade empírica. Esta é uma alternativa interessante a distância do cosseno, visto que esta métrica respeita a desigualdade triangular.
Resultados — t-SNE
Testou-se utilizar t-SNE para visualização do acervo, com objetivo de que as semelhanças entre processos fossem preservadas
Teste 1

Teste 2

Teste 3

Como os resultados não foram satisfatórios, esta técnica não foi utilizada na aplicação final.
