Warning: The `margin` argument should be constructed using the `margin()` function.
The `margin` argument should be constructed using the `margin()` function.
Mostrar códigos
theme_set(tema.graficos)
Mostrar códigos
### Funções ----# Função Sigmoidesigmoide <-function(x) {return(1/(1+exp(-x)))}# Função para realizar o forward propagation dados Phi e xforward_prop <-function(Phi, x, retornar_tudo = T) {# Organizando objetos f <-vector("list", 2) ; names(f) <-str_c("f", 0:1) h <-vector("list", 3) ; names(h) <-str_c("h", 0:2) a <-list(\(z) sigmoide(z), \(z) z) ; names(a) <-c("sigmoide", "Identidade")ifelse(is.matrix(x), h[[1]] <-t(x), h[[1]] <-as.matrix(x))# Propagando pela redefor(camada in1:length(a)) { f[[camada]] <- Phi$b[[camada]] + Phi$W[[camada]] %*% h[[camada]] h[[camada+1]] <- a[[camada]](f[[camada]]) # função de ativação }# Previsão y_hat <-as.double(h[[length(h)]])# Outputif(retornar_tudo) return(list(y_hat = y_hat, f = f, h = h))elsereturn(y_hat)}# Função para calcular a função de perdamse_cost <-function(y_true, y_hat) {return(mean((y_true - y_hat)^2))}# Função Derivada da Sigmoidederivada_sigmoide <-function(x) { sig <-sigmoide(x)return(sig * (1- sig))}# Função para realizar o back-propagation para um vetor theta, uma dada matriz design# e as observaçõesback_prop <-function(Phi, x, y){# Organizando os objetos aux <-forward_prop(Phi, x) a_linha <-list(\(z) derivada_sigmoide(z), \(z) rep(1, length(z))) Phi_grad <-list(W =vector(mode="list", 2), b =vector(mode="list", 2))### Em seguida, passamos para a implementação do back propagation g <--2*(y - aux$y_hat)/length(y)for (camada in2:1) { g <- g * a_linha[[camada]](aux$f[[camada]])if(!is.matrix(g)) g <-matrix(g, ncol=nrow(x)) Phi_grad$b[[camada]] <-rowSums(g) Phi_grad$W[[camada]] <- g %*%t(aux$h[[camada]]) g <-t(Phi$W[[camada]]) %*% g }### Final# Criamos um vetor com os gradientes de cada parâmetroreturn(Phi_grad)}### Gerando dados "observados"set.seed(22025)m.obs <-100000dados <-tibble(x1.obs=runif(m.obs, -3, 3), x2.obs=runif(m.obs, -3, 3)) %>%mutate(mu=abs(x1.obs^3-30*sin(x2.obs) +10), y=rnorm(m.obs, mean=mu, sd=1))# Taxa de aprendizagemepsilon <- .1# Número de iteraçõesM <-100# Divisão dos dados em treinamento, validação e testetreino <- dados[1:80000, ]val <- dados[80001:90000, ]teste <- dados[90001:nrow(dados), ]x_treino <- treino %>%select(x1.obs, x2.obs) %>%as.matrix()x_val <- val %>%select(x1.obs, x2.obs) %>%as.matrix()x_teste <- teste %>%select(x1.obs, x2.obs) %>%as.matrix()y_treino <- treino$yy_val <- val$yy_teste <- teste$y# Lista para receber os parâmetros estimados em cada iteraçãoPhi_est <-list()# Phi estrelaPhi_star <-list(W =list(W0 =matrix(rep(.1, 4), nrow=2), W1 =matrix(rep(.1, 2), nrow=1)), b =list(b0 =rep(.1, 2), b1 = .1))# Phi inicialPhi_0 <-list(W =list(W0 =matrix(rep(0, 4), nrow=2), W1 =matrix(rep(0, 2), nrow=1)), b =list(b0 =rep(0, 2), b1 =0))Phi_est[[1]] <- Phi_0# Vetores para receber as perdas de, respectivamente, treino e validação em cada iteraçãoperda_treino <- perda_val <-numeric(M)# Execuçãofor(i in1:M) {# Cálculo dos gradientes dos parâmetros grad <-back_prop(Phi = Phi_est[[i]], x = x_treino, y = y_treino)# Cálculo do custo de treino perda_treino[i] <-mse_cost(y_treino, forward_prop(Phi_est[[i]], x_treino)$y_hat)# Cálculo do custo de validação perda_val[i] <-mse_cost(y_val, forward_prop(Phi_est[[i]], x_val)$y_hat)# Atualização dos parâmetros Phi_est[[i+1]] <-map2(Phi_est[[i]], grad, \(x, y) map2(x, y, \(atual, passo) atual - epsilon * passo))}min_perda_treino <-min(perda_treino)min_perda_val <-min(perda_val)Phi_til <- Phi_est[which.min(perda_val)][[1]]
Considere os dados e os modelos descritos na Lista 2 para responder os itens a seguir. Caso deseje, use os códigos disponibilizados no arquivo de solução da Lista 2 e no final deste documento.
a)
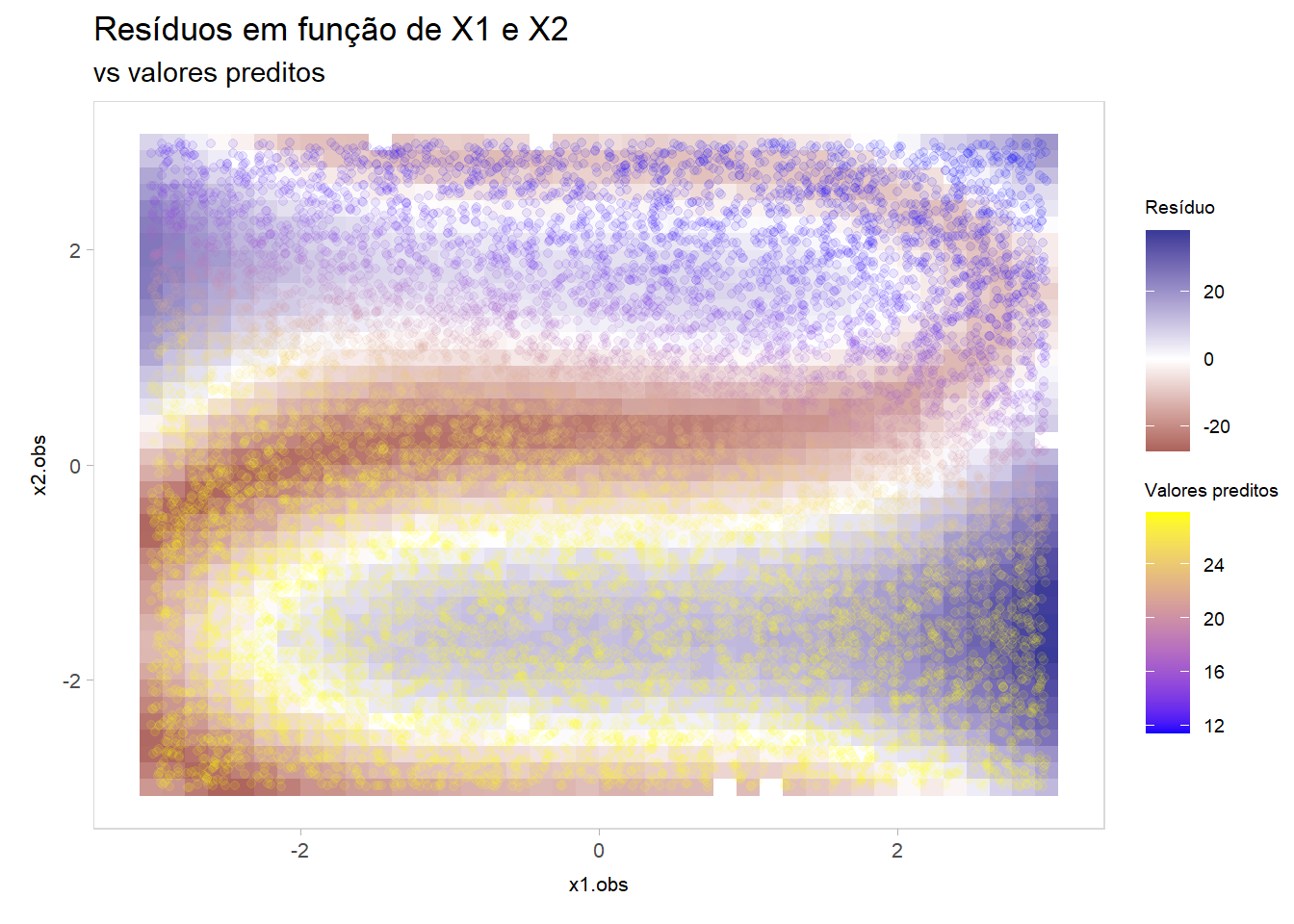
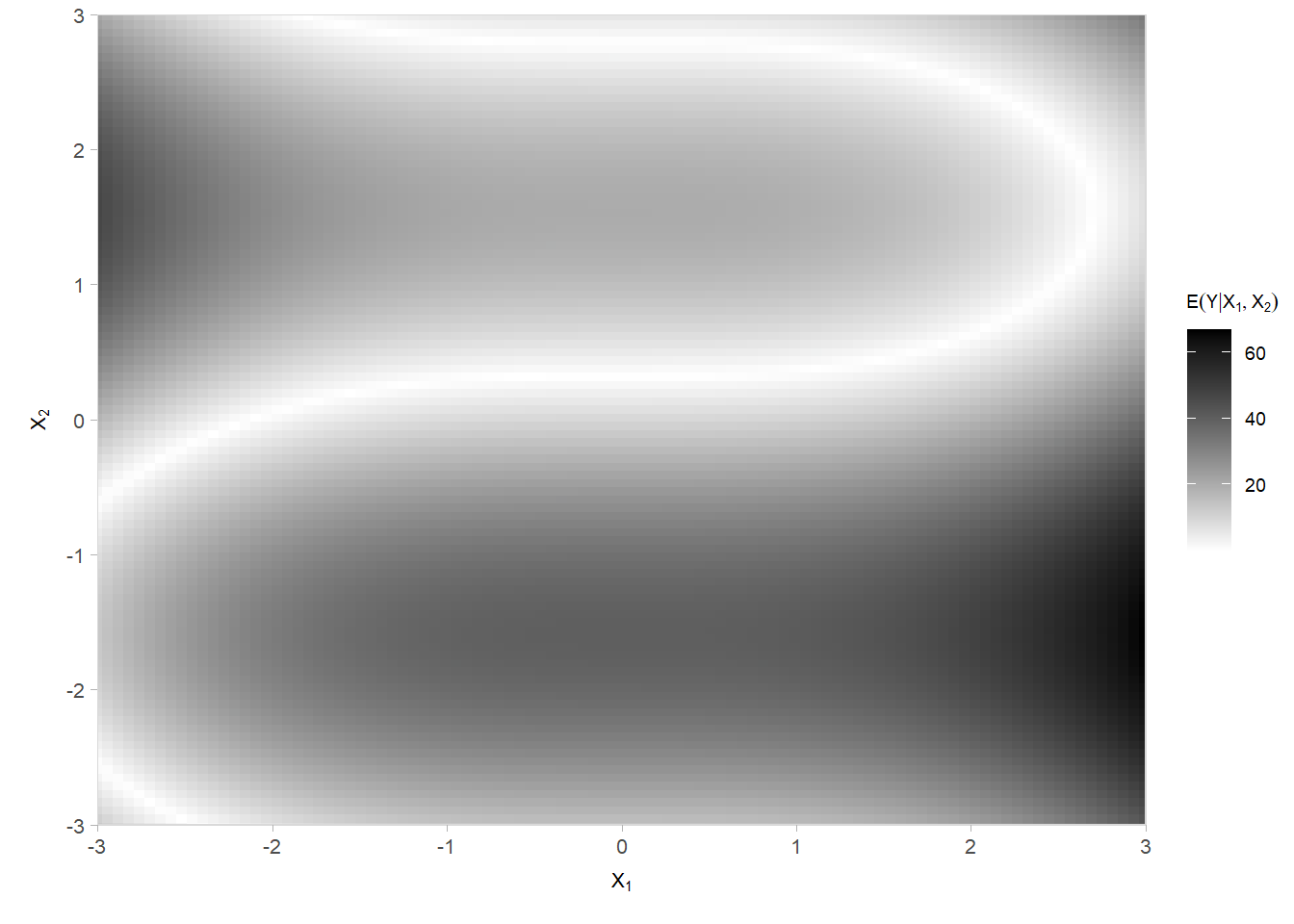
Calcule os valores previstos (\(\hat{y}_i\)) e os resíduos (\(y_i-\hat{y}_i\)) da rede no conjunto de teste e represente-os graficamente em função de \(X_1\) e \(X_2\). Dica: tome como base o código usado para a visualização da superfície \((E(Y|X_1, X_2), X_1, X_2)\). Altere o gradiente de cores e, se necessário, use pontos semi-transparentes. Analise o desempenho da rede nas diferentes regiões do plano. Há locais onde o modelo é claramente viesado ou menos acurado?
Nota-se portanto que a rede não consegue capturar o comportamento senoidal dos dados, visto que a estrutura geral ainda aparece no gráfico com os resíduos. Valores preditos próximo a região onde \(\mathbb{E}(Y|X_1,X_2)=0\) são muito altos, e valores muito minorados quando o verdadeiro valor de Y é alto (regiões negras no gráfico do processo gerador, e azul no gráfico de resíduos).
Podemos observar que a rede, basicamente, previu valores altos para \(x_2 < 0\) e valores baixos para \(x_2 > 0\).
b)
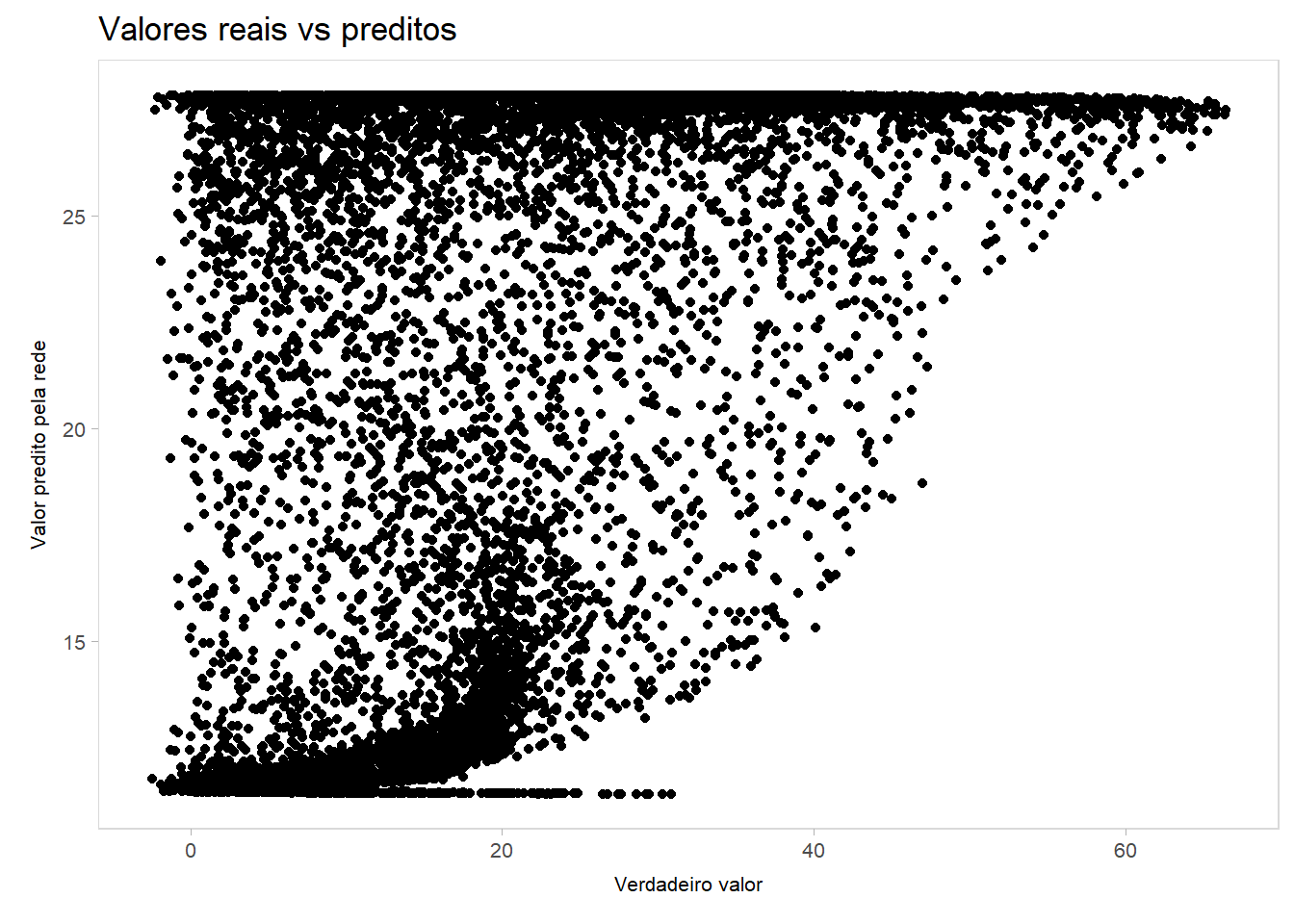
Faça um gráfico do valor observado (\(y_i\)) em função do valor esperado (\(\hat{y}_i=E(Y_i|x_{1i}, x_{2i})\)) para cada observação do conjunto de teste. Interprete o resultado.
Mostrar códigos
ggplot(teste, aes(x = y, y = y_hat_rna)) +geom_point() +labs(title ="Valores reais vs preditos",x ="Verdadeiro valor",y ="Valor predito pela rede")
Podemos tirar algumas conclusões deste gráfico. Se a rede fosse perfeita, esperaríamos algo como uma reta em 45º. Nota-se que existe, primeiramente, uma questão de domínio. Os verdadeiros \(y_i\) existentes no conjunto de teste assumem valores desde negativos (menor valor: -2.47) até 66.42. Por outro lado, os limites dos valores preditos \(\hat{y}_i\) começam em 11.4 e vão até 27.84. Isto é, não conseguem captar bem pequenos valores e nem grandes valores de \(Y\). Além disso, não conseguem capturar a estrutura do processo gerador de dados, visto que são previstos alguns grandes valores \(\hat{y}_i\) para pequenos valores \(y_i\). Percebe-se também uma relação com a função de ativação sigmoide escolhida, onde valores se “aglomeram” próximo aos valores de “chão” e de “teto” do intervalo suportado de predições pela rede, formando padrão característico de ajustes que utilizam esta função.
Solução
c)
Para cada \(k=2, \ldots, 300\), recalcule o gradiente obtido no item d) usando apenas as \(k\)-primeiras observações do banco de treinamento. Novamente, use \(\boldsymbol{\Phi}=\boldsymbol{\Phi}^\star\). Apresente um gráfico com o valor do primeiro elemento do gradiente (isso é, a derivada parcial \(\frac{\partial J}{\partial w_1}\)) em função do número de amostras \(k\). Como referência, adicione uma linha horizontal vermelha indicando o valor obtido na Lista 2, item d). Em seguida, use a função microbenchmark para comparar o tempo de cálculo do gradiente para \(k=300\) e \(k=80000\). Explique de que maneira os resultados dessa análise podem ser usados para acelerar a execução do item e) da Lista 2.
Solução
Mostrar códigos
valor_2d <-back_prop(Phi = Phi_star, x = x_treino, y = y_treino)$W[[2]][1]plan(multisession, workers =detectCores() -1)i <-300k_values <-2:iprimeiro_elemento <-future_map_dbl(k_values, function(k) { x_sub <- x_treino[1:k, 1:2, drop =FALSE] y_sub <- y_treino[1:k] res <-back_prop(Phi = Phi_star, x = x_sub, y = y_sub) res$W[[2]][1]})df <-tibble(valor = primeiro_elemento,k =2:i)ggplot(df, aes(x = k, y = valor)) +geom_line() +geom_hline(yintercept = valor_2d, color ="red")
Mostrar códigos
mbm <-microbenchmark(k_300 = { x_sub <- x_treino[1:300, 1:2, drop =FALSE] y_sub <- y_treino[1:300] res <-back_prop(Phi = Phi_star, x = x_sub, y = y_sub) res$W[[2]][1] },k_80000 = { x_sub <- x_treino[1:80000, 1:2, drop =FALSE] y_sub <- y_treino[1:80000] res <-back_prop(Phi = Phi_star, x = x_sub, y = y_sub) res$W[[2]][1] },times =100)autoplot(mbm)
Pela primeira Figura, podemos ver que para valores relativamente baixos de \(k\), já é possível recuperar um valor próximo para o primeiro elemento \(\frac{\partial J}{\partial \omega_1}\). Pela segunda Figura, notamos que, apesar de implementação eficiente e vetorizada, logicamente o tempo para avaliar em \(k=300\) é significativamente inferior a avaliação do gradiente para \(k=80000\), estando entre pelo menos 10 e até mais de 100 vezes mais rápida.
Desta forma, é possível introduzir o conceito de mini-batches, onde iremos avaliar o gradiente para uma pequena quantidade amostral a cada iteração, tendo em vista o resultado ser convergente e acelerar o tempo de execução do algoritmo. Este conceito, se implementado, já tornaria a execução do item e) da lista 2 mais rápido.
Como este paradigma lida com quantidades massivas de observações e contas a partir dela, pequenos ganhos acumulados podem ser o diferencial entre esperar meses ou horas para ajuste de uma rede neural mais complexa.
d)
Ajuste sobre o conjunto de treinamento um modelo linear normal (modelo linear 1) \[
Y_i \sim N(\beta_0 + \beta_1 x_{1i} + \beta_2 x_{2i}, \sigma^2)
\] usando a função lm do pacote R (ou outra equivalente). Em seguida, inclua na lista de covariáveis termos quadráticos e de interação linear. Isso é, assuma que no modelo linear 2, \[
E(Y|x_1, x_2) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1^2 + \beta_4 x_2^2 + \beta_5 x_1 x_2.
\] Compare o erro quadrático médio no conjunto de teste dos dois modelos lineares acima com o da rede neural ajustada anteriormente. Qual dos 3 modelos você usaria para previsão? Justifique sua resposta.
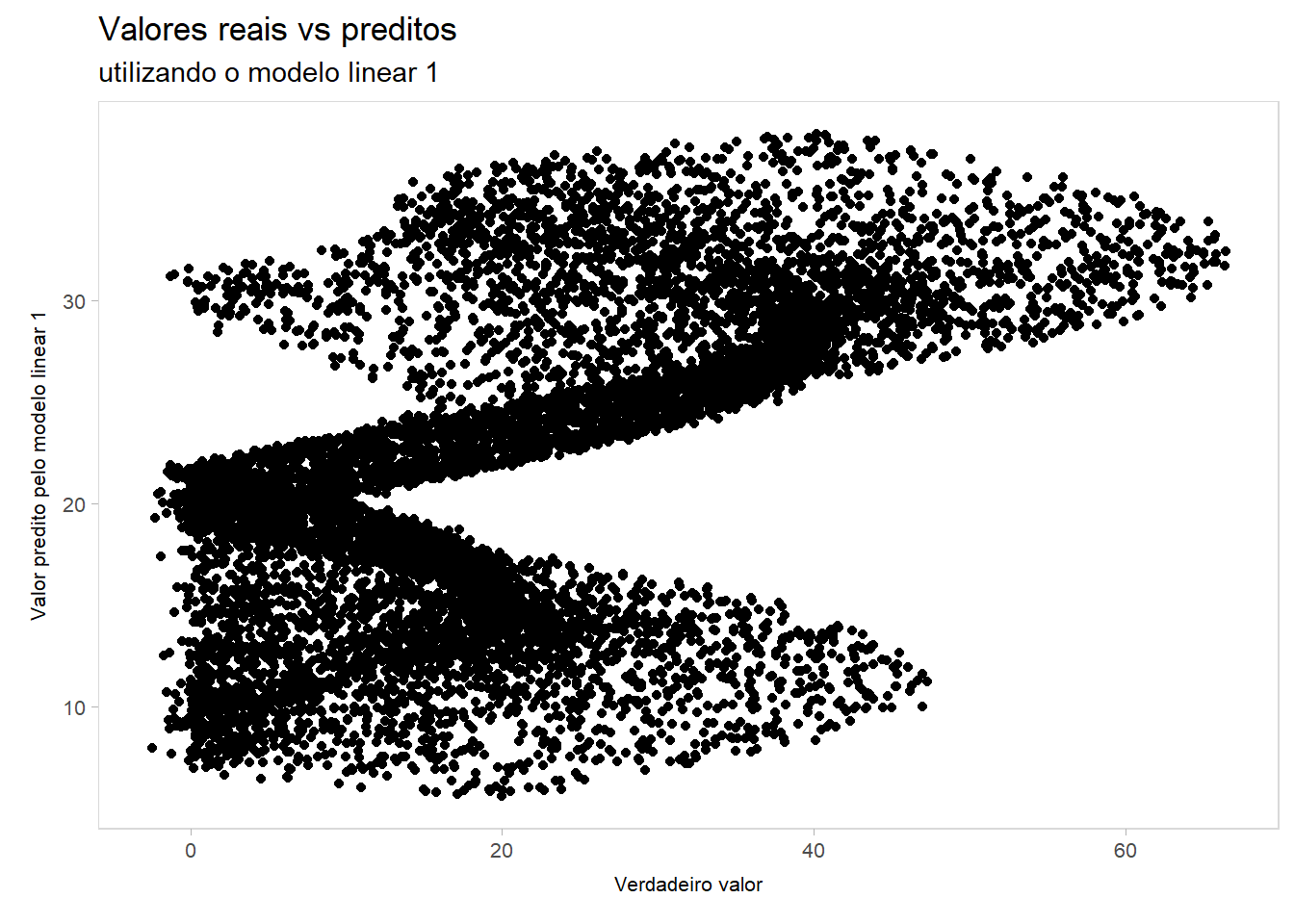
ggplot(teste, aes(x = y, y = y_hat_lm1)) +geom_point() +labs(title ="Valores reais vs preditos",subtitle ="utilizando o modelo linear 1",x ="Verdadeiro valor",y ="Valor predito pelo modelo linear 1")
Mostrar códigos
ggplot(teste, aes(x = x1.obs, y = x2.obs, z = residuos_lm1)) +stat_summary_2d(bins =40) +scale_fill_gradient2() +labs(title ="Resíduos em função de X1 e X2",subtitle ="utilizando o modelo linear 1",fill ="Resíduo")
Modelo linear 2
Mostrar códigos
ggplot(teste, aes(x = y, y = y_hat_lm2)) +geom_point() +labs(title ="Valores reais vs preditos",subtitle ="utilizando o modelo linear 2",x ="Verdadeiro valor",y ="Valor predito pelo modelo linear 2")
Mostrar códigos
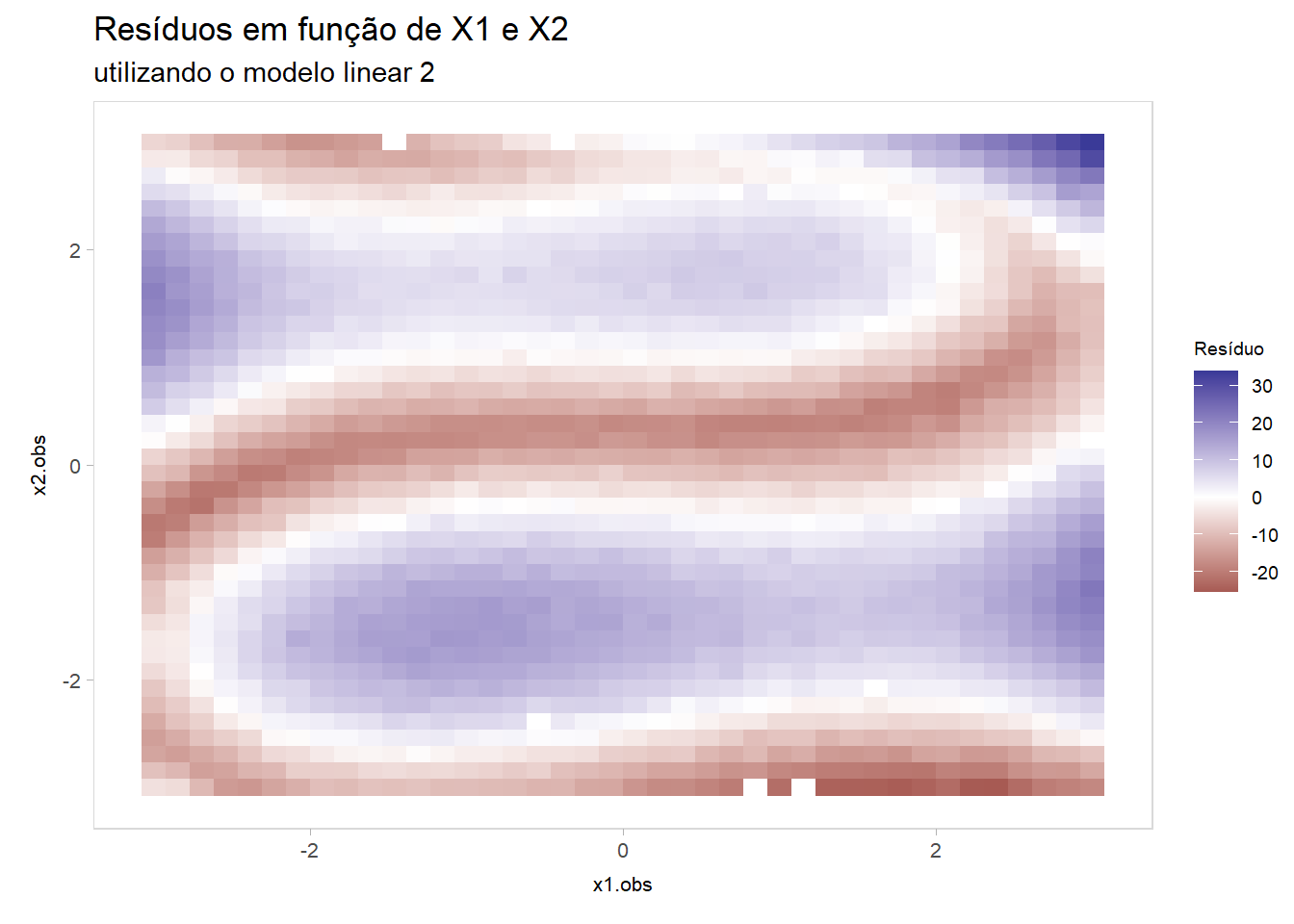
ggplot(teste, aes(x = x1.obs, y = x2.obs, z = residuos_lm2)) +stat_summary_2d(bins =40) +scale_fill_gradient2() +labs(title ="Resíduos em função de X1 e X2",subtitle ="utilizando o modelo linear 2",fill ="Resíduo")
Optar por analisar qualquer um destes modelos é uma escolha de Sofia. Temos uma rede neural simples que, conforme discutido (inclusive em aula), performa muito mal. Por outro lado, temos um modelo linear composto por dois parâmetros tal como disponibilizados, e outro modelo linear com features artesanais — representando algo próximo do estado da arte de regressão linear —, e, em todos os casos, nada se aproxima do verdadeiro processo gerador de dados. Observando o gráfico de resíduos em relação a x1 e x2, todos os três modelos falham em capturar o comportamento dos dados.
Por coerência epistemológica, já que a função de perda escolhida para todos os três modelos foi o erro quadrático médio, deve-se então escolher o modelo linear dois, definido por
\[
E(Y|x_1, x_2) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1^2 + \beta_4 x_2^2 + \beta_5 x_1 x_2,
\] por ter sido o que obteve menor EQM para realizar predição. Para análise de média, é o que esta métrica sugere ser o modelo que menos errará.
e)
Para cada modelo ajustado (os dois lineares e a rede neural), descreva o efeito no valor esperado da variável resposta causado por um aumento de uma unidade da covariável \(x_1\)?
Solução
Modelo linear 1
Para o primeiro modelo linear, a interpretação é clara, simples e direta (e, também, errada, isto é, pouco ajustada, neste caso específico).
Mostrar códigos
kable(t(linear1$coefficients))
(Intercept)
x1.obs
x2.obs
21.87751
1.222191
-4.246881
O aumento de uma unidade em x1, mantido x2 constante, aumenta a esperança da variável resposta em 1.2221908 unidades.
Modelo linear 2
Para o segundo modelo linear, a resposta não é tão direta.
Fixado algum valor qualquer para \(x_2\), o efeito marginal de \(x_1\) sobre \(\mathbb{E}(Y)\) aumenta em \(2(0.7144143) = 1.428829\) unidades para cada acréscimo unitário em \(x_1\). Para este modelo, já é necessário um certo malabarismo com as palavras para a interpretação, visto que este não é exatamente o efeito em sí, mas a taxa de variação do efeito conforme aumenta \(x_1\).
Rede neural
No caso da rede neural, por sua natureza não linear, não é possível interpretar diretamente o efeito global do acréscimo de uma unidade de \(x_1\). Este efeito poderar minorar, majorar ou manter \(\mathbb{E}(Y)\) constante para diferentes regiões.
Podemos fazer um gráfico para ilustrar a situação. Mantendo \(x_2\) constante em algum valor arbitrário (no caso, a média: 0), podemos rodar a rede, sob os parâmetros definidos como melhores ao final da lista 2, e observar o comportamento do aumento de unidades entre -3 e 3 (domínio de \(x_1\)) e os efeitos observados em \(\hat{y}\) para este \(x_2\) fixo.
Portanto, o efeito de \(x_1\) na \(\mathbb{E}(y)\), como diria didi mocó, vareia.
f)
Novamente, para cada um dos 3 modelos em estudo, calcule o percentual de vezes que o intervalo de confiança de 95% (para uma nova observação!) capturou o valor de \(y_i\). Considere apenas os dados do conjunto de teste. No caso da rede neural, assuma que, aproximadamente, \(\frac{y_i - \hat{y}}{\hat{\sigma}} \sim N(0, 1)\), onde \(\hat{\sigma}\) representa a raiz do erro quadrático médio da rede no conjunto de validação. Comente os resultados. Dica: para os modelos lineares, use a função predict(mod, interval="prediction").
Solução
Mostrar códigos
teste <-cbind(teste,predict(linear1, newdata = teste[,1:2], interval="prediction")[,2:3])teste <- teste %>%mutate(prop_linear1 =ifelse(y >= lwr & y <= upr,1,0)) %>%select(-c(lwr,upr))teste <-cbind(teste,predict(linear2, newdata = teste[,1:2], interval="prediction")[,2:3])teste <- teste %>%mutate(prop_linear2 =ifelse(y >= lwr & y <= upr,1,0)) %>%select(-c(lwr,upr))teste <- teste %>%mutate(lwr_rna = y_hat_rna -1.96*sqrt(min_perda_val),upr_rna = y_hat_rna +1.96*sqrt(min_perda_val)) %>%mutate(prop_rna =ifelse(y >= lwr_rna & y <= upr_rna,1,0)) %>%select(-c(lwr_rna,upr_rna))prop <-tibble(`Modelo linear 1`=round(mean(teste$prop_linear1) *100,2),`Modelo linear 2`=round(mean(teste$prop_linear2) *100,2),`Rede Neural`=round(mean(teste$prop_rna) *100,2))kable(prop,caption ="Porcentagem de valores do conjunto de teste capturados no intervalo 95% de predição para cada modelo")
Porcentagem de valores do conjunto de teste capturados no intervalo 95% de predição para cada modelo
Modelo linear 1
Modelo linear 2
Rede Neural
95.18
96.75
94.63
Notamos resultados muito parecidos para todos os três modelos, e interpretativamente proporcionais a análise do erro quadrático médio. De fato, o modelo linear 2 captura mais valores, e a rede neural é a que menos captura valores. Entretando, a diferença é muito pequena, e a grande maioria dos valores é capturado pelo intervalo em todos os modelos.
Vale comentar que esta é uma métrica de avaliação muito ruim neste caso, visto que o intervalo de confiança 95% é muito amplo, então valores mal centralizados ainda estão em sua grande maioria compreendidos em até 1.96 desvios-padrão. Mas neste caso, o desvio padrão é da magnitude de 12.22, o que contém quase o domínio inteiro de \(y\) dentro deste intervalo. (ex: uma previsão centrada na média de y do conjunto de teste, i.é: \(\bar{y}_{teste}\) = 21.75, terá como intervalo 95% valores inferiores a zero e superiores a 45).
g)
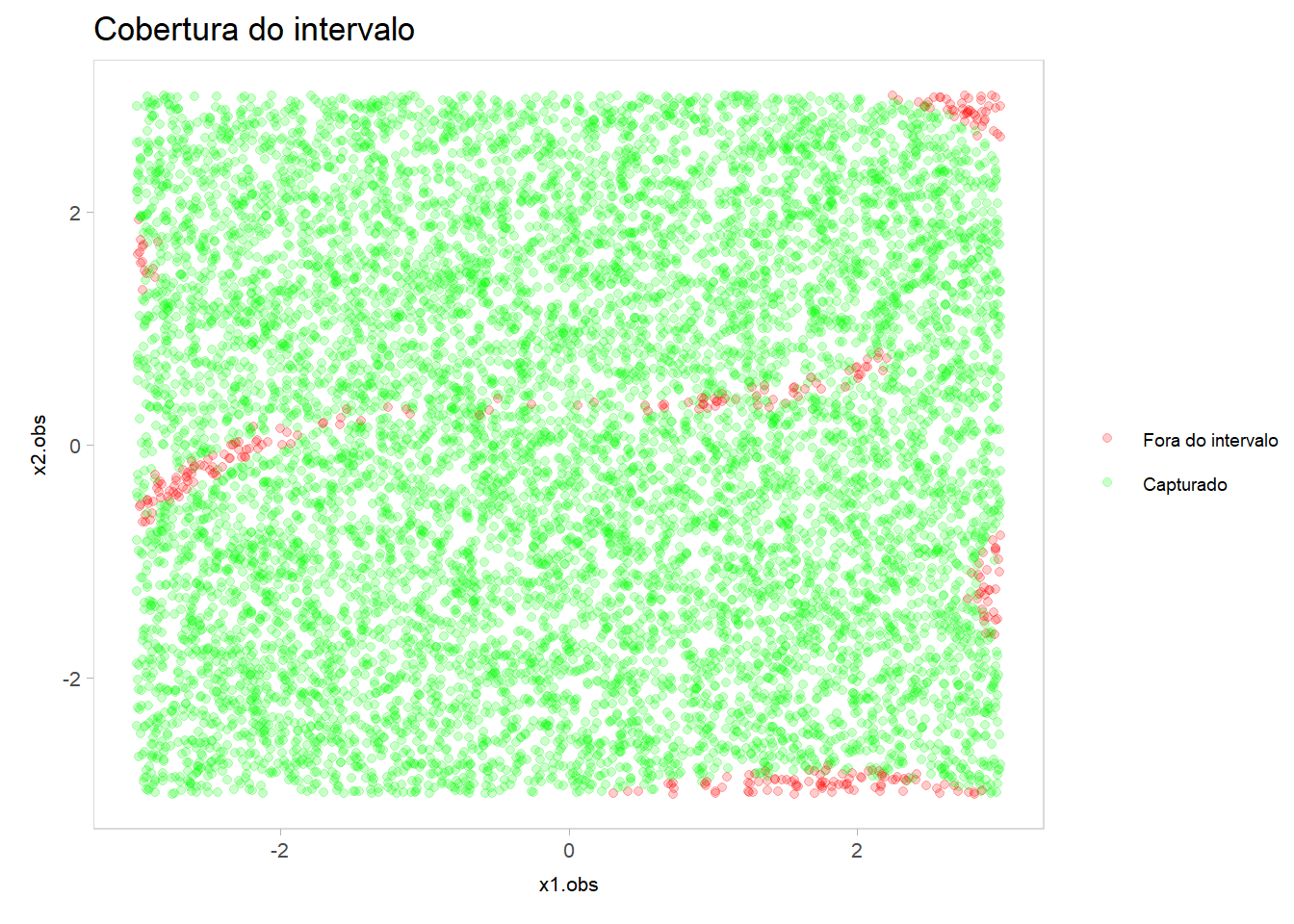
Para o modelo linear 2, faça um gráfico de dispersão entre \(x_1\) e \(x_2\), onde cada ponto corresponde a uma observação do conjunto de teste. Identifique os pontos que estavam contidos nos respectivos intervalos de confianças utilizando a cor verde. Para os demais pontos, use vermelho. Comente o resultado.
Solução
Mostrar códigos
ggplot(teste, aes(x = x1.obs, y = x2.obs)) +geom_point(aes(color =factor(prop_linear2)), alpha =0.2) +scale_color_manual(values =c("0"="red", "1"="green"),labels =c("Fora do intervalo", "Capturado")) +labs(title ="Cobertura do intervalo",color ="")
O gráfico apresenta o comportamento que já era esperado pelo modelo linear. Temos um processo gerador de dados claramente não linear e, apesar do modelo conter alguns padrões não lineares na sua construção, a forma artesanal e errônea de tentar construir features não lineares não foi de encontro ao padrão senoidal existente no processo gerador. Desta forma, podemos avaliar a má qualidade de ajustes locais justamente nas regiões características da forma do processo gerador de dados, onde o modelo retorna previsões muito pobres para regiões de valores muito altos ou muito baixos segundo o real comportamento dos dados. Isto é, mesmo com um intervalo de confiança de 95% bastante permissivo, não é possível obter um ajuste local aceitável para alguns pontos, a partir de relações entre covariáveis tradicionalmente utilizadas pelo paradigma de modelagem com regressão linear, para um processo gerador tão específico.
Sem conhecimento do processo gerador de dados, tentar construir features artesanalmente, isto é, declarando “na mão” quando da utilização da função lm(), é uma tarefa quase impossível, e que demanda muito conhecimento do problema. Redes neurais, por outro lado, são capazes de aprender padrões complexos a partir dos dados, sem a necessidade de um conhecimento prévio tão específico. Contudo, como visto na análise da rede neural simples implementada, é necessário um cuidado especial com a arquitetura da rede, funções de ativação e parâmetros de treinamento para que o modelo consiga capturar tais padrões complexos.