O monitoramento da taxa de churn é essencial para a saúde de uma empresa, pois altas taxas de churn podem indicar baixa aderência entre o perfil do cliente e o produto oferecido. Desta forma, é crucial buscar detectar os fatores que estão contribuindo para este descompasso, bem como realizar previsões para o futuro próximo, com o objetivo de delinear ações estratégicas, táticas e operacionais.
Neste contexto, a ciência de dados se apresenta como uma ferramenta eficaz, e a análise aqui desenvolvida visa diagnosticar os principais determinantes do churn e desenvolver modelos que auxiliem tanto na previsão quanto na compreensão dos fatores associados ao cancelamento de clientes em um plano de saúde.
Para analisar os possíveis fatores relacionados a evasão do cliente no plano de saúde, coletou-se informações individuais de cada cliente, incluindo características sociodemográficas, como sexo, faixa de renda e unidade da federação em que reside, além de atributos relacionados ao produto contratado, como valor da mensalidade e tempo de adesão ao plano.
Na etapa de análise exploratória de dados, analisou-se as relações bivariadas da variável resposta e suas variáveis explicativas, bem como buscou-se encontrar relações multivariadas entre as covariáveis e a variável resposta. Incluiu-se neste relatório todas as análises bivariadas (com exceção de titularidade, por ausência de variabilidade), bem como a relação multivariada detectada — a interação de renda, inadimplência e cancelamento.
Na etapa de modelagem, buscou-se dois objetivos:
Um modelo preditivo com excelentes métricas, que pudesse ser utilizado com segurança para previsão do risco de cancelamento de cada cliente;
Um modelo explicativo, no qual fosse possível extrair interpretação de seus coeficientes para interpretação e diagnóstico de parâmetros, com objetivo de formular sugestões para ações estratégicas, que ainda preservasse métricas aceitáveis de ajuste.
Neste sentido, julgou-se pertinente selecionar e utilizar dois modelos diferentes, um para cada um destes objetivos. O modelo com melhores métricas em absoluto foi utilizado para previsão, enquanto um modelo auxiliar com métricas ligeiramente inferiores foi utilizado para interpretação de coeficientes e sugestão de ações estratégicas.
Neste relatório técnico, estão descritas as etapas de diagnóstico, análise e modelagem aplicada a este conjunto de dados — com aporte metodológico estatístico descrito na seção de metodologia —, bem como resultados obtidos e conclusões. Esta análise foi exitosa em encontrar um modelo preditivo bem ajustado, bem como em identificar e metrificar o impacto das características mais importantes para aumento ou diminuição de chance de cancelamento do plano de saúde, possibilitando assim a formulação de conclusões assertivas e sugestões de ações estratégicas baseadas em dados para reversão do cenário de alto churn.
Metodologia
Para executar esta análise, utilizou-se a linguagem de programação Python, versão 3.12.3, junto com bibliotecas comuns de análise de dados, como pandas, numpy e scipy; bibliotecas de visualização como matplotlib, seaborn e plotly; bibliotecas de ciência de dados como Scikit-learn; além de outras bibliotecas necessárias para tarefas específicas no decorrer da análise, como geopandas, unicodedata, IPython, shap e warnings.
A criação e execução do jupyter notebook foi realizada no Visual Studio Code, enquanto este relatório técnico foi elaborado com Quarto, por meio da IDE RStudio. Para organização do projeto, criou-se um diretório privado no GitHub com os arquivos separados em pastas específicas, garantindo a inteligibilidade do projeto.
Para o escopo desta análise, fora fornecido um conjunto de dados com 101.063 observações (instâncias) e 12 variáveis (características). Alguns clientes, identificados pelo seu id único, apareciam mais de uma vez na tabela, configurando duplicata. Dessa forma, foram removidas as duplicidades, mantendo apenas uma observação por cliente. Dessas características, encontra-se a variável alvo (ou variável resposta — ou, simplesmente, variável), que corresponde ao status de cancelamento do cliente (churn). Conjuntamente, encontrava-se 10 variáveis explicativas (ou covariáveis), sendo elas: titularidade, faixa de renda, idade na adesão, tempo de plano em meses, sexo, quantidade de consultas, quantidade de internações, valor da mensalidade, unidade da federação e status de inadimplência do cliente. Essas covariáveis foram utilizadas para explicação do cancelamento, conforme seu potencial explicativo. Encontrava-se ainda uma coluna de identificação única de cada cliente, não utilizada nesta análise por não conter valor preditivo.
A quantidade de instâncias fornecidas é mais que suficiente para realizar modelagem preditiva. No contexto do estudo de dados, apesar de não existir um número analítico (estando este entre 1.000 e 10.000 instâncias), técnicas estatísticas clássicas como teste t para diferença de médias, teste não paramétrico de Kruskal-Wallis e outros utilizados para comparar grupos, tornam-se excessivamente sensíveis, identificando como significativas diferenças de magnitude irrelevante. Neste contexto, apenas técnicas mais sofisticadas, como as de aprendizado de máquina, são robustas para avaliar diferenças entre grupos e metrificar o impacto de características relevantes. Pode-se ainda remover algumas instâncias com inconsistências graves, isto é, que possuem problemas de preenchimento ou dados absurdos, em consonância com o princípio de good data over big data, como idade na adesão negativa ou tempo de plano em meses negativo, visto que estas instâncias não agregam valor ao modelo e podem prejudicar a análise. Além disso, esse processo também contemplou o tratamento de casos de separação perfeita, que poderiam comprometer a estabilidade de modelos explicativos. A quantidade de instâncias restantes permite ainda realizar a divisão de treino e teste, com massa de dados adequada para ambas as etapas.
Para análise exploratória dos dados, optou-se por visualizações gráficas e apresentação de estatísticas resumo em tabelas ou quadros. Para a modelagem de dados, utilizou-se diversos modelos contidos no scikit-learn, como regressão logística, árvore de decisão, árvore com bagging, florestas aleatórias e naive bayes.
Para avaliação dos modelos, utilizou-se métricas de avaliação recomendadas no escopo da ciência de dados, como acurácia (previsões corretas pelo total de previsões), precisão (verdadeiros positivos pelo total de positivos previstos), sensibilidade (verdadeiros positivos pela soma de verdadeiros positivos e falsos negativos), especificidade (verdadeiros negativos pela soma de falsos positivos e verdadeiros negativos), além do F1-Score e área sob a curva, além de visualizações como matriz de confusão, curva ROC e variable importance plot. Além disso, utilizou-se a técnica de validação cruzada para escolha de hiperparâmetros e validação dos modelos, com divisão dos dados em 80% para treino e 20% para teste e validação cruzada.
Destaca-se ainda que o balanceamento dos dados entre categorias das características, em especial para a variável resposta, pode representar um desafio para a modelagem. Algumas covariáveis como unidade da federação tiveram que ser agregadas em regiões para possibilitar a modelagem, pelo grave desbalanceamento de classes. Para a variável resposta, existiam mais clientes com cancelamento positivo que negativo, entretanto a diferença era pequena para uma grande massa de dados, o que em geral não é problemático para a maioria dos modelos. Ainda assim, quando da divisão entre treino e teste, estratificou-se as amostras em relação a esta variável, garantindo a proporção de cancelamentos e não cancelamentos em ambos os conjuntos de treino e teste.
Aplicou-se ainda técnicas para lidar com dados ausentes, como imputação ou remoção de instâncias em alguns casos. Para a modelagem, construiu-se algumas features baseadas nas covariáveis originais, além de procedimentos de pré processamento de dados, inclusive da seleção de features e covariáveis relevantes para cada caso. Detalhes da utilização destas técnicas em cada caso serão explicitadas nas seções de análise e modelagem.
Nesta seção, iremos conduzir uma análise exploratória dos dados, contendo o cálculo da taxa de churn, análises bivariadas da variável ‘cancelado’ pelas demais covariáveis do conjunto de dados, bem como análise exploratória multivariada, onde buscaremos captar relações de interação entre mais de duas variáveis.
Note que a covariável titularidade não foi incluida neste relatório, visto que não apresentava variação — todos os clientes do conjunto de dados eram titulares do plano.
Taxa de churn
Mostrar o código
churn_rate = df['cancelado'].value_counts(normalize=True)['SIM'] *100churn_rate =f"{churn_rate:.2f}".replace(".", ",")print(f"Taxa global de churn: {churn_rate}%")
Taxa global de churn: 58,85%
Observa-se uma taxa de churn superior a 50% nos dados, indicando uma alta evasão de clientes do plano de saúde. Esta taxa é preocupante, visto que pode indicar problemas com o produto ou com o perfil do cliente atendido pela empresa.
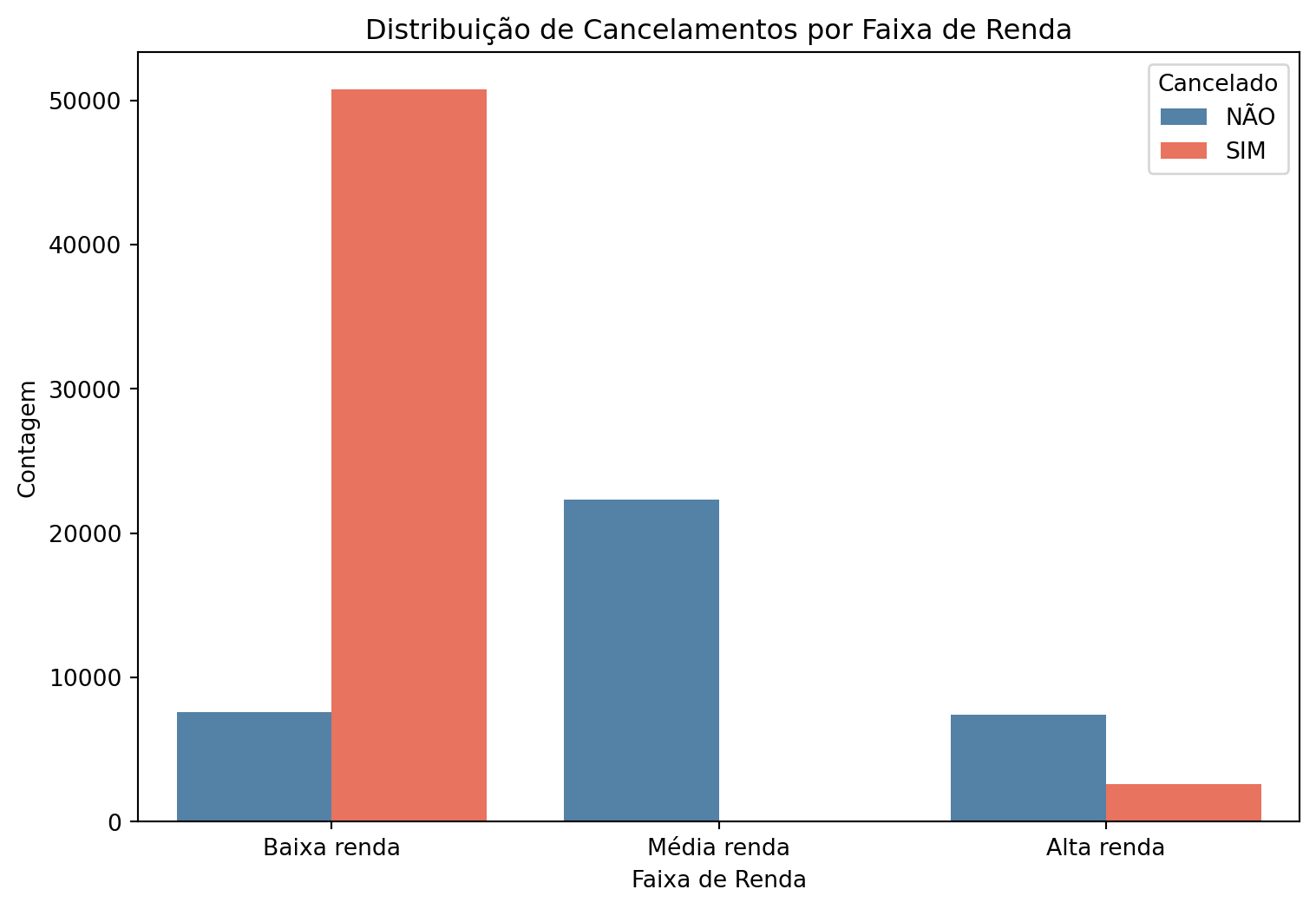
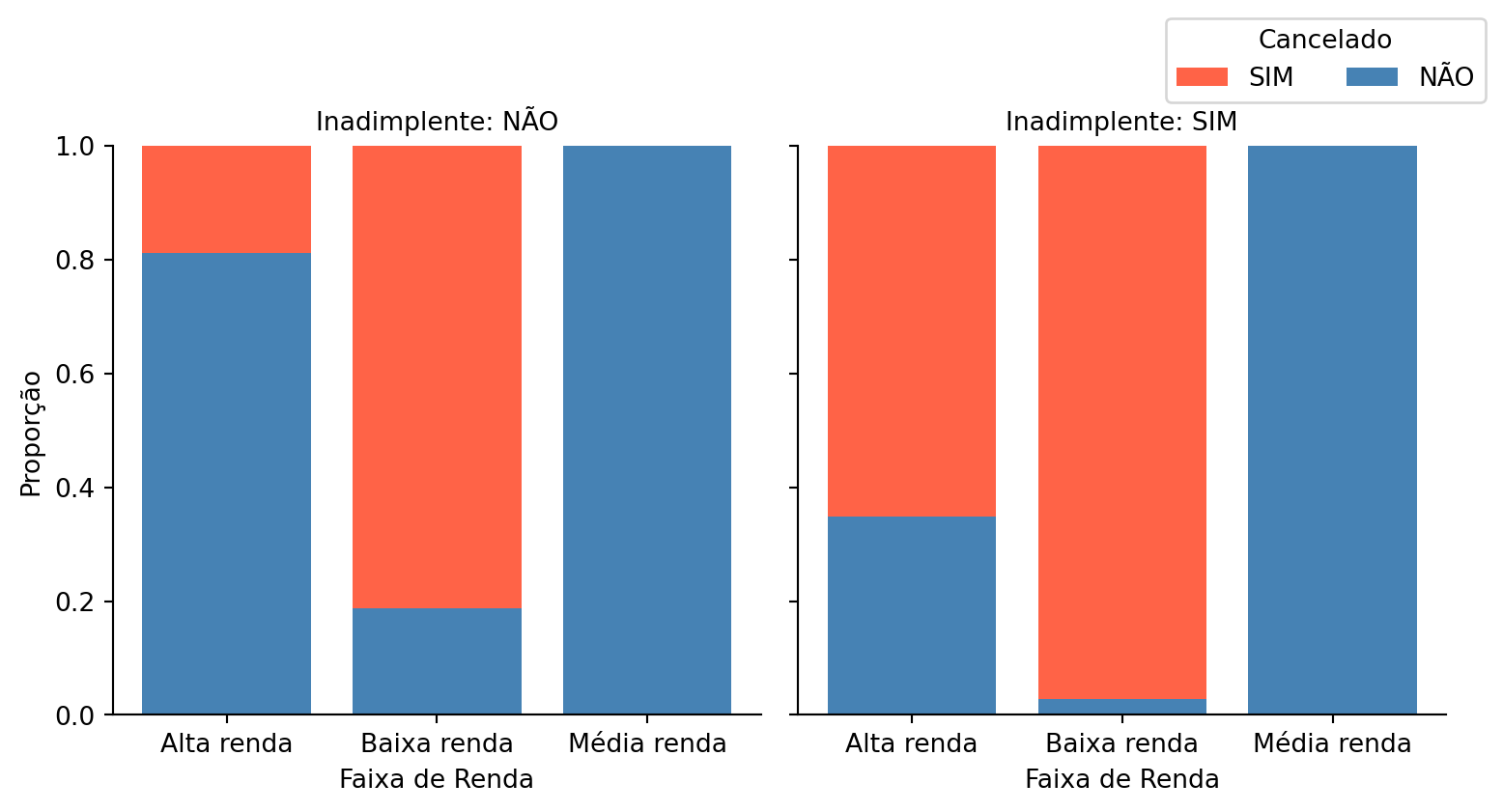
Em geral, clientes de baixa renda tendem a ter alta taxa de cancelamento (86,98% dos clientes de baixa renda cancelaram). Dentre os clientes de renda média, não houve cancelamento algum. Para os clientes de alta renda, a evasão foi de 26,3%.
Estes resultados indicam que podem ser realizadas ações para clientes de faixas de renda específicas — em especial os de baixa renda — na busca da reversão da alta taxa de churn.
Cancelamento por idade na adesão
Mostrar o código
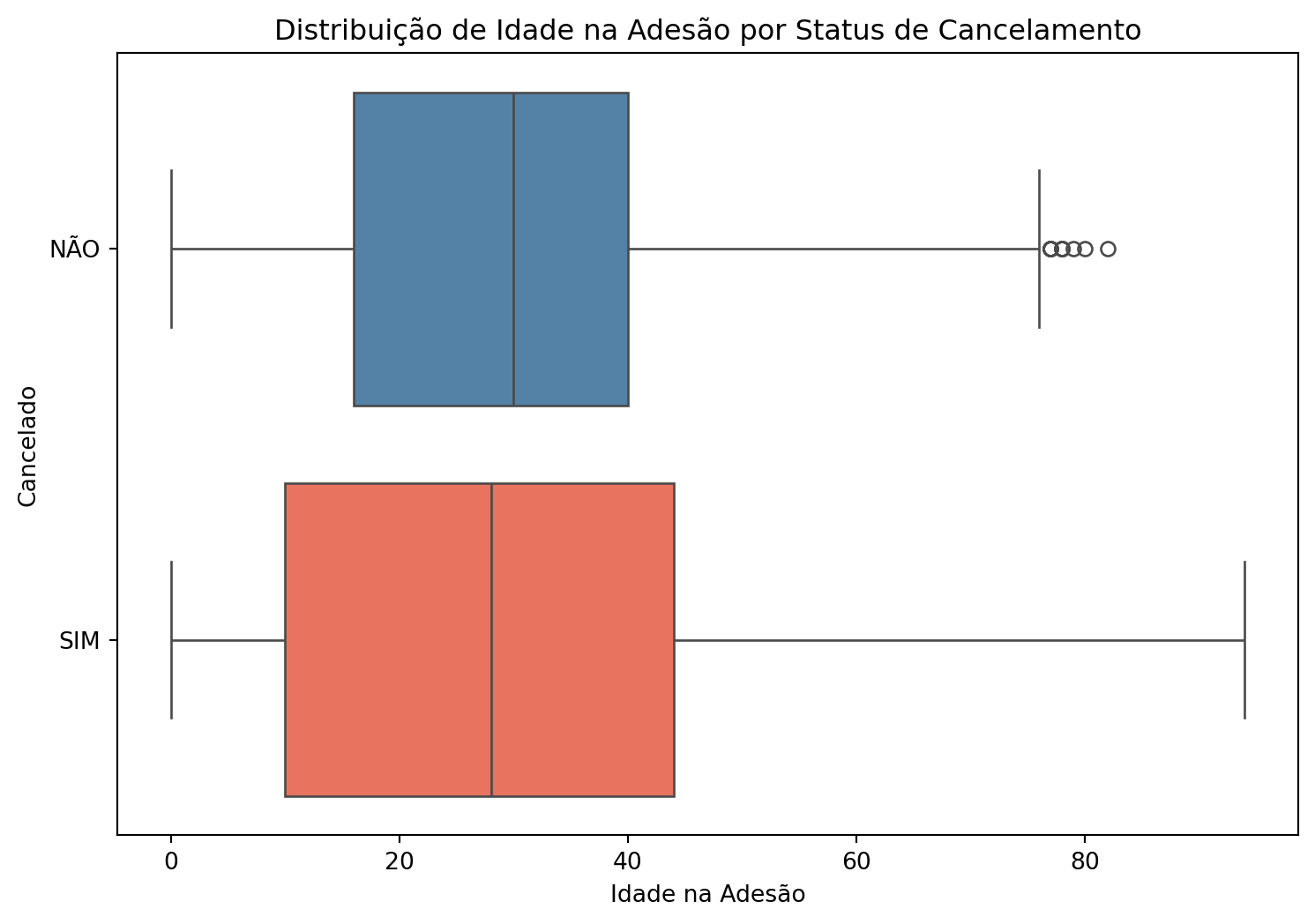
idade_na_adesao = df.groupby('cancelado', observed=True)['idadenaadesao'].describe().transpose().round(2)styled_idade_na_adesao = ( idade_na_adesao.fillna(0) .round(2) .style .format("{:,.2f}", subset=idade_na_adesao.columns,thousands=".", decimal=",", na_rep="0"))display(styled_idade_na_adesao)plt.figure(figsize=(9, 6))sns.boxplot(data=df, y='cancelado', x='idadenaadesao', palette=['steelblue','tomato'])plt.title('Distribuição de Idade na Adesão por Status de Cancelamento')plt.xlabel('Idade na Adesão')plt.ylabel('Cancelado')plt.show()
cancelado
NÃO
SIM
count
37.356,00
53.418,00
mean
29,17
29,43
std
16,91
21,13
min
0,00
0,00
25%
16,00
10,00
50%
30,00
28,00
75%
40,00
44,00
max
82,00
94,00
Em relação à idade na adesão, os clientes que não cancelaram apresentam idade mediana de 30 anos, estando os primeiro e terceiro quartis nas idades 16 e 40 anos, respectivamente. Os clientes que cancelaram apresentam idade mediana de 28 anos, estando os primeiro e terceiro quartis nas idades 10 e 44 anos. Em geral, as idades média e mediana dos grupos são similares, em que clientes que cancelaram o plano apresentam idade mais heterogênea que clientes que não cancelaram.
Cancelamento por tempo de plano em meses
Mostrar o código
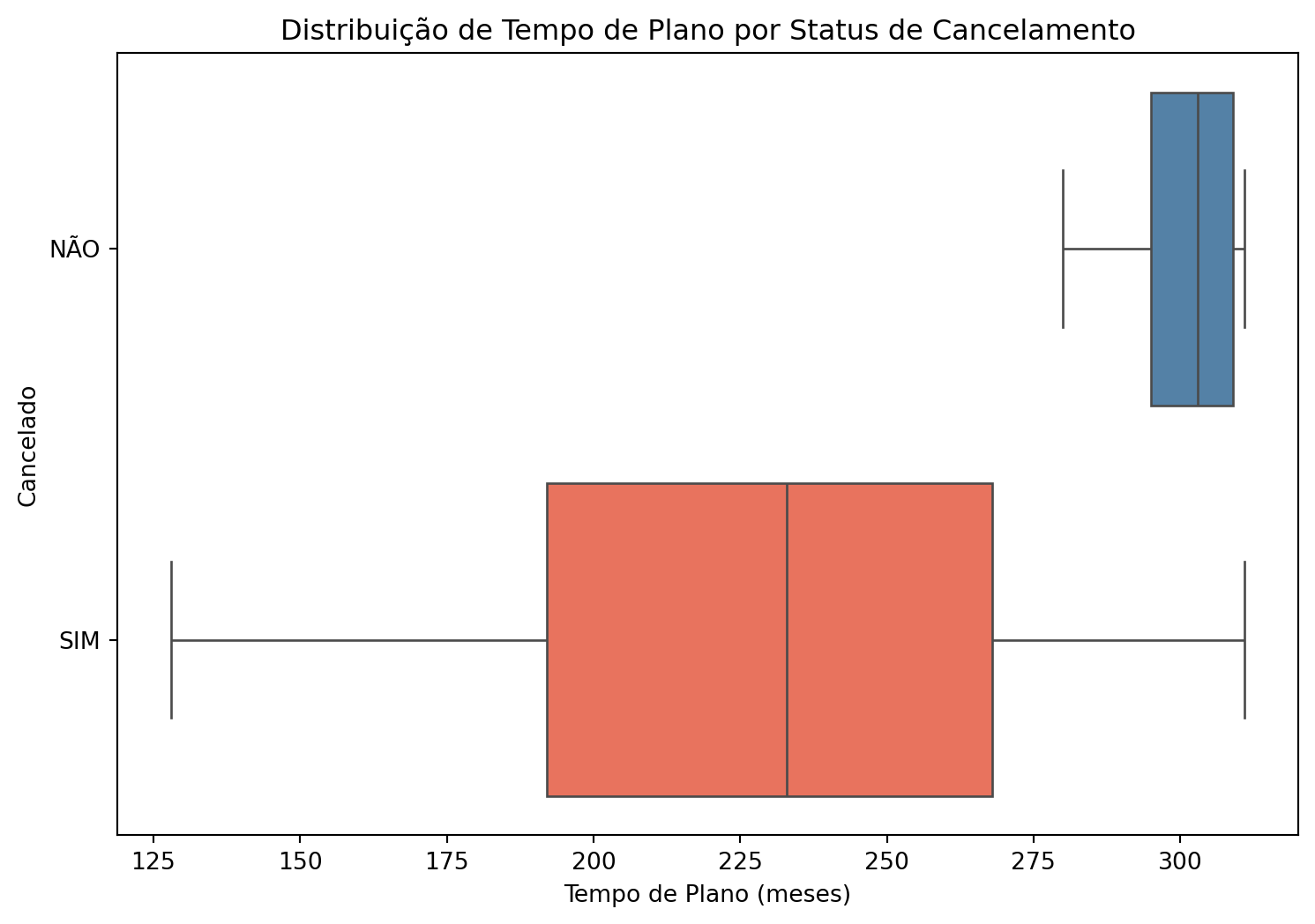
tempo_de_plano_meses = df.groupby('cancelado', observed=True)['tempo_de_plano_meses'].describe().transpose().round(2)styled_tempo_de_plano_meses = ( tempo_de_plano_meses.fillna(0) .round(2) .style .format("{:,.2f}", subset=tempo_de_plano_meses.columns,thousands=".", decimal=",", na_rep="0"))display(styled_tempo_de_plano_meses)plt.figure(figsize=(9, 6))sns.boxplot(data=df, y='cancelado', x='tempo_de_plano_meses', palette=['steelblue','tomato'])plt.title('Distribuição de Tempo de Plano por Status de Cancelamento')plt.xlabel('Tempo de Plano (meses)')plt.ylabel('Cancelado')plt.show()
cancelado
NÃO
SIM
count
37.356,00
53.418,00
mean
301,42
229,05
std
7,72
45,73
min
280,00
128,00
25%
295,00
192,00
50%
303,00
233,00
75%
309,00
268,00
max
311,00
311,00
Quanto ao tempo do plano em meses, os clientes que cancelaram o plano apresentam média e mediana inferiores aos que não cancelaram o plano. Os clientes que não cancelaram o plano apresentam tempo mínimo de 280 meses, valor este superior ao terceiro quartil do tempo de permanência dos clientes que cancelaram. Para clientes com tempo igual ou superior a 295 meses de permanência, a massa de dados se concentra dentre os que não cancelaram o plano, indicando uma probabilidade de cancelamento desprezível após este tempo de permanência, se analisado somente esta variável.
Este resultado preliminar indica que ações de permanência no plano podem ser convenientes para reversão da alta taxa de churn, visto que marginalmente clientes que estão no plano a mais tempo apresentam menor propensão ao cancelamento deste.
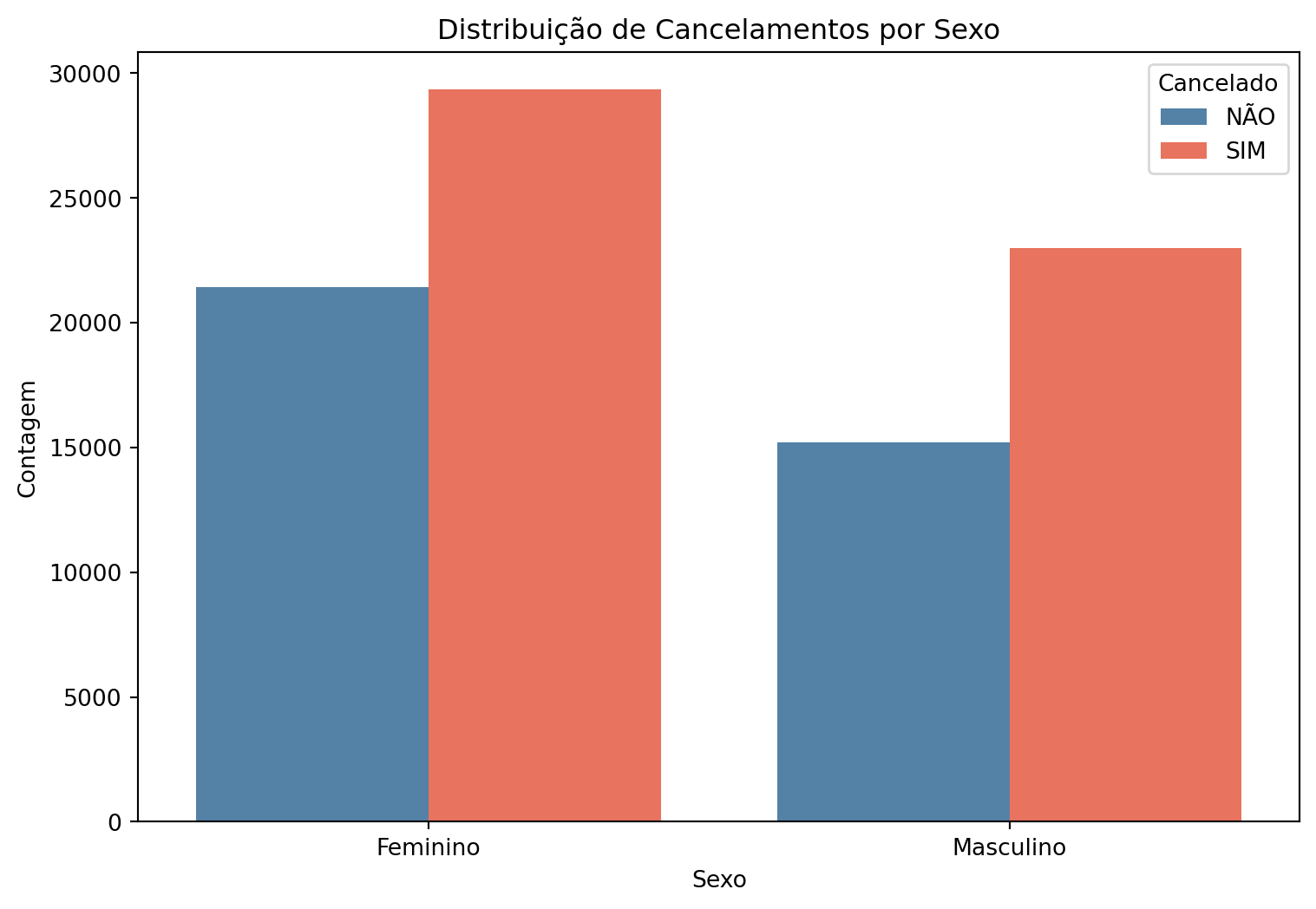
Existem mais clientes do sexo feminino do que clientes do sexo masculino. Existe uma taxa ligeiramente superior de cancelamento entre clientes do sexo feminino do que clientes do sexo masculino. Esta taxa não aparenta ser significativa, possivelmente tratando-se de ruído branco.
O mapa coroplético evidencia diferenças estaduais e regionais com relação a taxa de churn. Regiões como sudeste e sul apresentam relativa homogeneidade, enquanto centro-oeste, norte e, principalmente, nordeste, apresentam maior heterogeneidade de taxa entre os estados. É possível que políticas de reversão possam ser aplicadas a nível estadual ou regional. Entretanto, a massa de dados se concentra em clientes do sudeste, o que pode afetar a sensibilidade de um modelo preditivo baseado nestes dados utilizando esta covariável. Desta forma, uma agregação possível é por região do cliente — ainda que isto possa mascarar heterogeneidades regionais, esta pode ser uma etapa necessária para obter um modelo melhor ajustado.
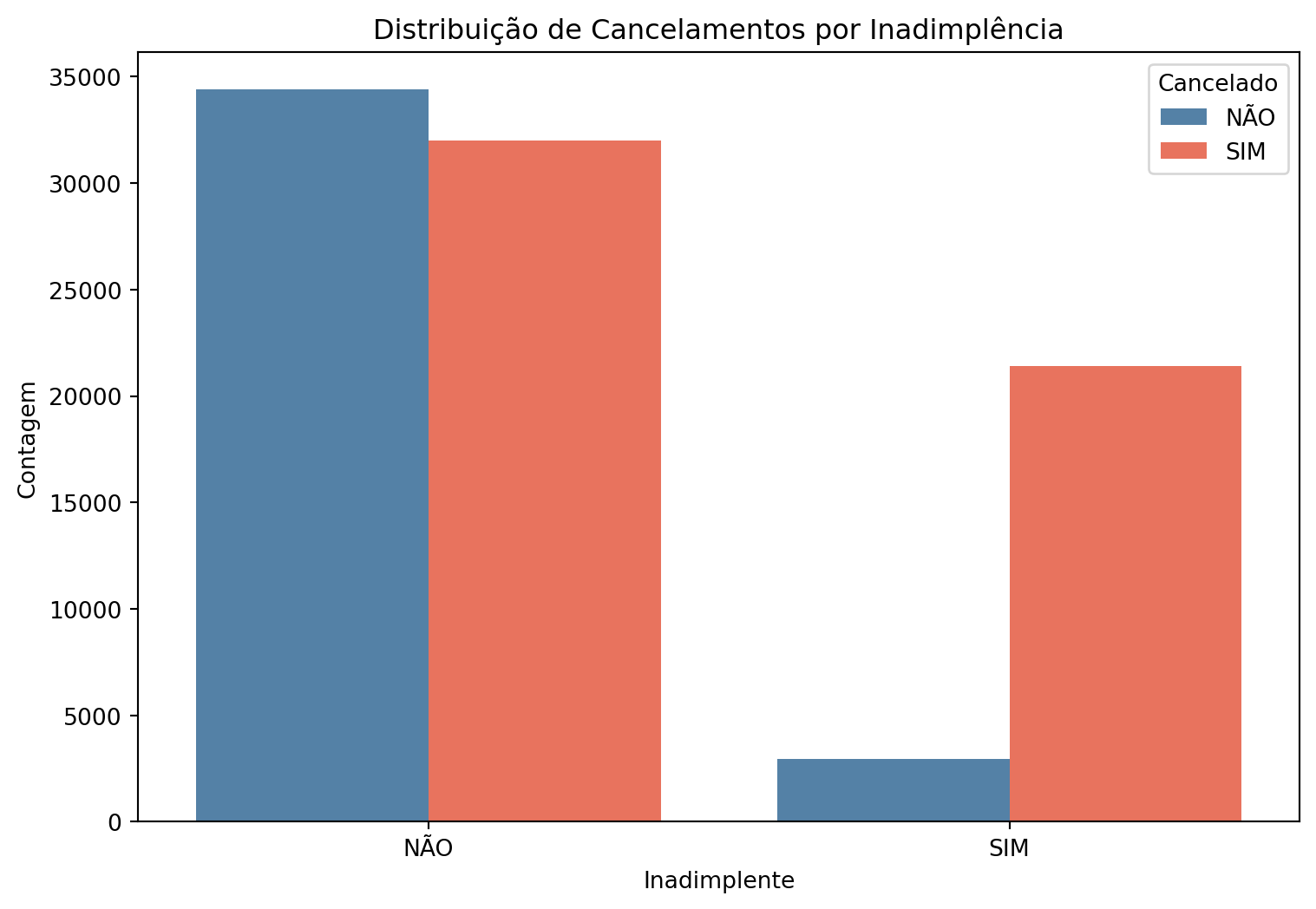
Nota-se que os clientes adimplentes são maioria. Dentre os clientes inadimplentes, a grande maioria cancelou o plano. Dentre os adimplentes, a distribuição é razoavelmente uniforme entre cancelamento e não cancelamento.
Analisando marginalmente o efeito desta covariável, podemos dizer que a inadimplência do cliente aparenta ser fator significativo para cancelamento do plano. Ações de permanência para clientes inadimplentes podem ser delineadas para reversão do cenário de alto churn.
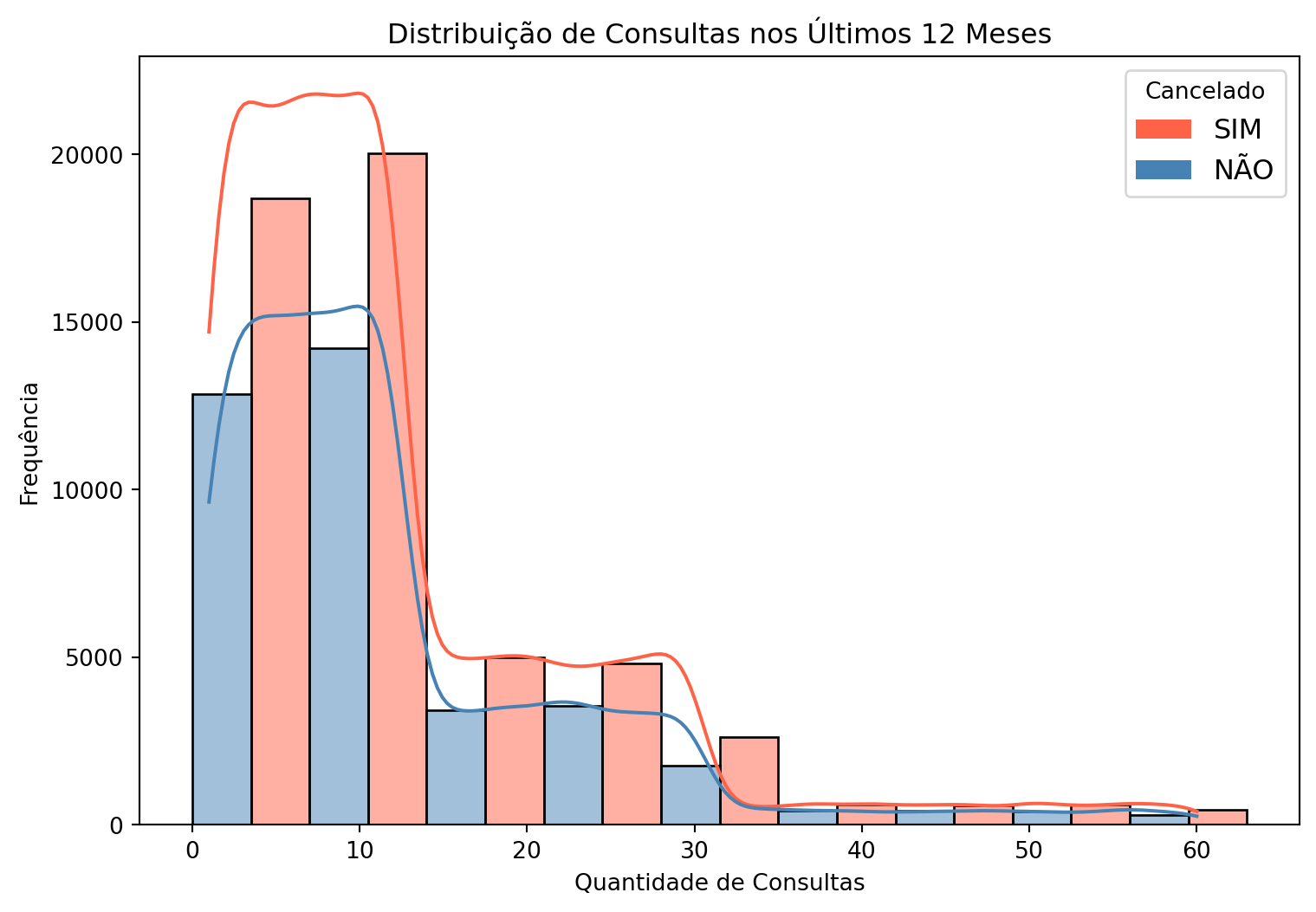
Cancelamento por quantidade de consultas do cliente nos últimos 12 meses
A quantidade de consultas nos últimos 12 meses apresenta estatísticas de ordem e localização proporcionais se comparado clientes que cancelaram ou não o plano. Isto indica que esta variável, isoladamente, não explica bem o cancelamento do plano.
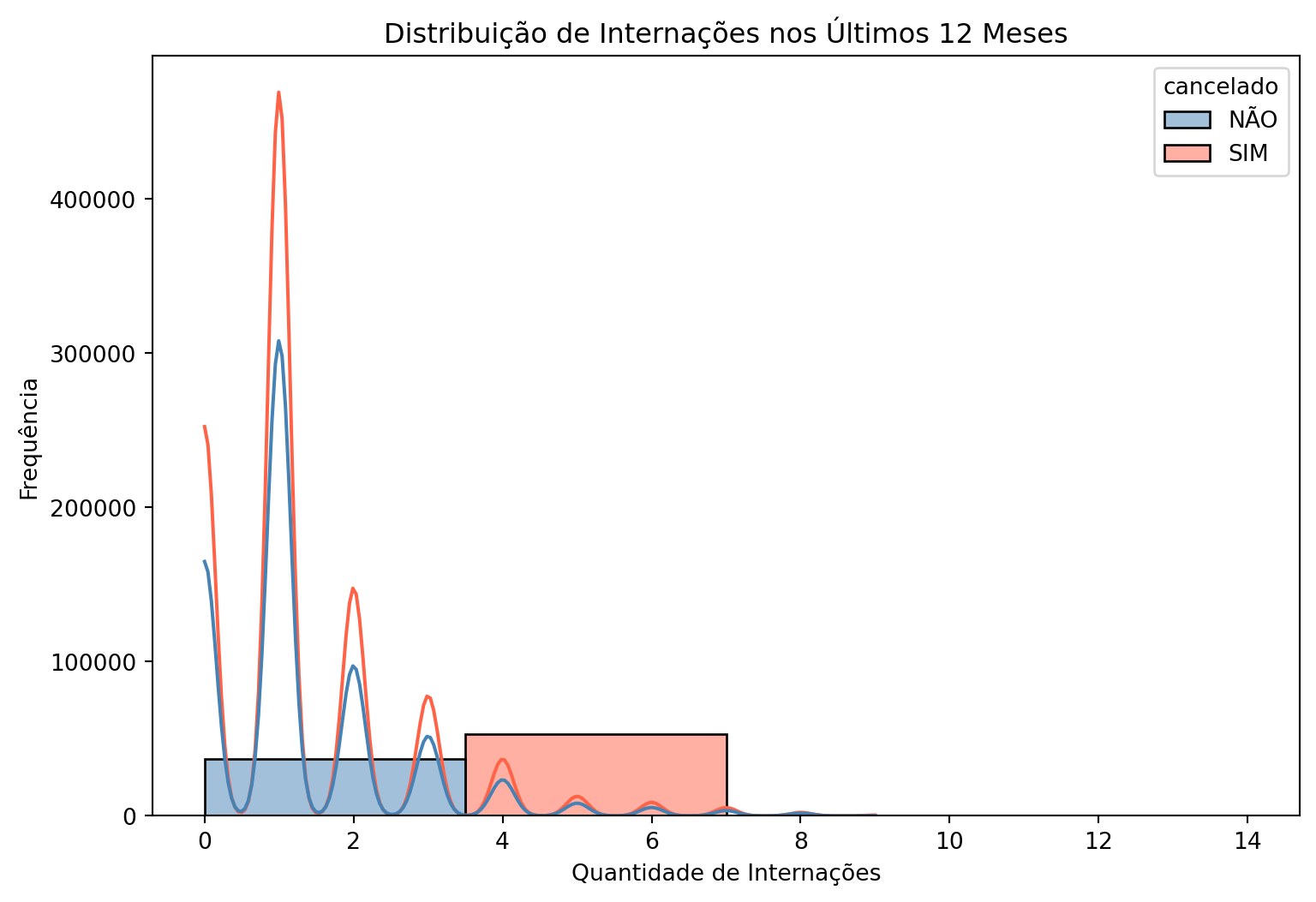
Cancelamento por quantidade de internações do cliente nos últimos 12 meses
A quantidade de internações nos últimos 12 meses apresenta estatísticas de ordem e localização proporcionais ou exatamente iguais se comparado clientes que cancelaram ou não o plano. Isto indica que esta variável, isoladamente, não explica bem o cancelamento do plano.
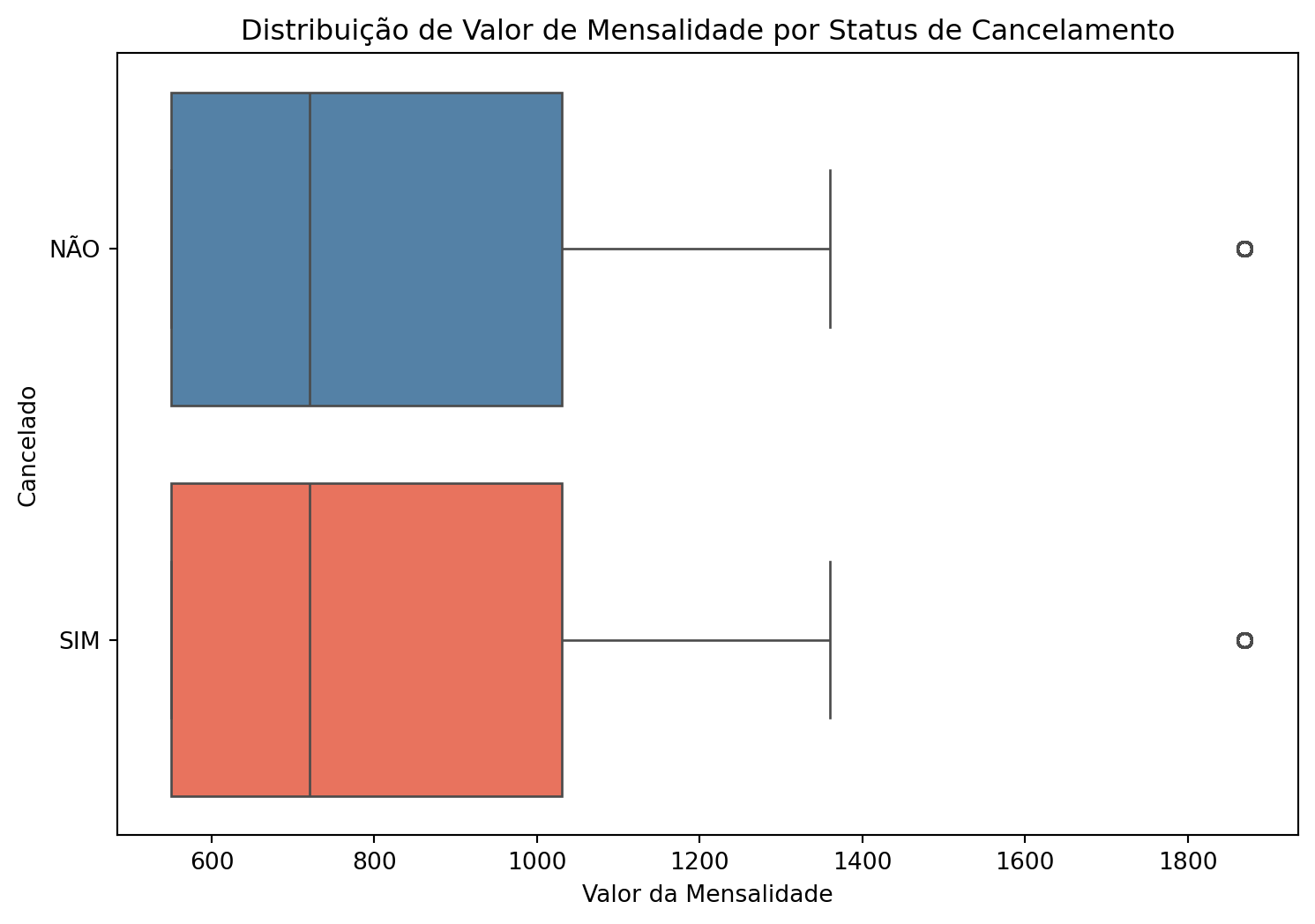
Cancelamento por valor da mensalidade do plano
Mostrar o código
valor_mensalidade = df.groupby('cancelado', observed =True)['valor_mensalidade'].describe().transpose().round(2)styled_valor_mensalidade = ( valor_mensalidade.fillna(0) .round(2) .style .format("{:,.2f}", subset=valor_mensalidade.columns,thousands=".", decimal=",", na_rep="0"))display(styled_valor_mensalidade)plt.figure(figsize=(9, 6))sns.boxplot(data=df, y='cancelado', x='valor_mensalidade', palette=['steelblue','tomato'])plt.title('Distribuição de Valor de Mensalidade por Status de Cancelamento')plt.xlabel('Valor da Mensalidade')plt.ylabel('Cancelado')plt.show()
cancelado
NÃO
SIM
count
23.644,00
33.731,00
mean
898,77
928,94
std
349,60
426,84
min
550,00
550,00
25%
550,00
550,00
50%
720,00
720,00
75%
1.030,00
1.030,00
max
1.870,00
1.870,00
O valor da mensalidade apresenta estatísticas de ordem e localização similares em ambos os grupos (clientes que cancelaram, clientes que não cancelaram). Isto indica que esta variável não explica bem o cancelamento ou não do plano, se analisada isoladamente.
Ao analisar conjuntamente a faixa de renda, inadimplência e cancelamento, nota-se que para os clientes de alta renda, o inadimplento é variável significativa para indicar o cancelamento ou não do plano. Isto indica que pode ser necessária uma política específica para clientes inadimplentes de alta renda, visto que este perfil predomina para o cancelamento do plano ante clientes de alta renda não inadimplentes.
Conclusão da análise exploratória
Comparando os grupos de clientes que cancelaram ou não o plano utilizando análises bivariadas, nota-se que dos dados fornecidos, apenas alguns apresentam indícios de significância na determinação do cancelamento ou não do plano.
As variáveis mais significativas — visualmente — foram renda, tempo em meses do plano, unidade da federação do cliente e inadimplência.
Além disso, nota-se interação entre a faixa de renda e o inadimplento para explicar o cancelamento do plano dentre os clientes de alta renda. A maior parte dos clientes de alta renda que cancelaram o plano estavam inadimplentes.
Testes estatísticos para diferença de média ou mediana nos grupos não são adequados, pelo tamanho do conjunto de dados (90.774 instâncias, após remoção de dados absurdos e duplicatas), pois seriam viesados pelo tamanho amostral e detectariam significância em diversos casos pouco significativos.
O agrupamento das unidades da federação em regiões (Norte, Nordeste, Sudeste, Centro-Oeste e Sul) manteria a significância da diferença entre os grupos, entretanto poderia mascarar algumas heterogeneidades regionais (Como o estado do Piauí, que difere significativamente da tendência dos demais estados do Nordeste). Este agrupamento será realizado na modelagem pois a quantidade de instâncias é insuficiente na estratificação dos grupos para algumas unidades da federação.
Nota-se portanto que a alta taxa de churn aparenta estar mais relacionada com o perfil do cliente do que com o produto da empresa em si, visto que covariáveis mais relacionadas ao produto, como quantidade de consultas, quantidade de internações e valor da mensalidade não apresentaram diferenças entre clientes que cancelaram ou não o plano. Isto pode indicar maior necessidade de compreensão e ações relacionadas ao perfil do cliente do que a readequação do produto oferecido.
Modelagem
A análise exploratória é uma etapa fundamental para a compreensão preliminar das covariáveis, especialmente em conjuntos de dados com grande volume de informações. Ela permite identificar padrões marginais e potenciais associações entre características, servindo como base para hipóteses e direcionamento da modelagem. No entanto, seu caráter descritivo a torna insuficiente para a obtenção de conclusões inferenciais ou para a avaliação do impacto isolado de cada variável.
Para alcançar esses objetivos — estimar o risco de cancelamento e identificar os fatores mais relevantes para a evasão de clientes — é necessário recorrer a métodos de modelagem estatística e aprendizado de máquina. Dada a natureza do problema, que envolve uma variável resposta binária (cancelamento ou não), optou-se por utilizar algoritmos de classificação.
Foram testados tanto modelos mais simples e interpretáveis, como a regressão logística e a árvore de decisão, quanto algoritmos mais robustos e complexos, como florestas aleatórias e árvores com bagging. Essas abordagens permitem comparar diferentes estratégias de modelagem em termos de desempenho preditivo e interpretabilidade. A seleção final dos modelos considerou não apenas métricas de ajuste, mas também a capacidade de fornecer subsídios para decisões estratégicas.
Política para valores ausentes
Diversos tratamentos podem ser realizados no conjunto de dados para lidar com dados ausentes. Ainda na fase da análise exploratória, optou-se por remover algumas instâncias com valores ausentes, sendo elas: idade na adesão ao plano inferior a zero anos ou superior a 100 anos; tempo de plano em meses inferior à zero e unidade da federação não preenchida. Em muitos casos, cada instância é preciosa e devemos evitar ao máximo sua eliminação. Entretanto, neste contexto, a quantidade de observações é suficientemente robusta, permitindo a exclusão de um pequeno número delas sem prejuízo à análise. Para além disso, julguei que o mau preenchimento destas colunas poderia indicar problema no preenchimento de demais informações da instância, o que poderia levar a um viés no modelo, caso fossem imputados valores mais coerentes, como tempo médio ou mediano, ou ainda rótulo de unidade da federação (que, nesse caso, quase certamente seria preenchido com valores mais frequentes — isto é, estados localizados no sudeste).
Para valores ausentes nas covariáveis numéricas referentes a quantidade de consultas e internações, julguei apropriado realizar a imputação com a mediana, tendo visto que:
estas covariáveis não apresentavam grande diferença entre clientes que cancelaram ou não na análise exploratória;
as respectivas distribuições incorriam em forte fuga à normalidade, sendo mais indicado a imputação pela mediana neste caso, em detrimento da média.
A covariável sexo também apresentava valores ausentes e, visto sua marginal insignificância aparente na etapa exploratória na determinação do cancelamento ou não por parte do cliente, optou-se por simplesmente não incluir esta covariável na modelagem.
Construção de features
Na análise exploratória, construiu-se apenas uma feature: Região (regiao), baseada na unidade da federação do cliente. A construção de features, isto é, novas covariáveis como modificações e/ou combinação das covariáveis existentes, podem ser cruciais na etapa de modelagem, ao custo de redução do entendimento e explicabilidade do modelo ao final. Desta forma, evitou-se construir features mais complexas em uma primeiro momento, para preservar a explicabilidade do modelo.
O modelo geral
Será considerada para modelagem a variável dependente “cancelado” (SIM/NÃO) como resposta, sendo explicada pelas demais covariáveis selecionadas, à excessão de: id_cliente, titularidade, sexo e unidade da federação.
id_cliente é simplesmente a identificação única de cada cliente, não havendo sentido em sua inserção para modelagem (servindo apenas para remoção de duplicatas); sexo por problemas de valores ausentes e baixo indicativo de significância na análise exploratória; titularidade pela ausência de variância; e unidade da federação pelo baixo número de instâncias para algumas unidades da federação, o que confundia o modelo — para esta, optou-se pela feature agregada Região (regiao).
Pré processamento
Uma camada adicional de filtragem foi adicionada nesta etapa: a remoção das instâncias cuja renda observada foi “Média”. Isto por que, conforme observado na etapa exploratória, existe a separação perfeita — nenhum cliente de renda média cancelou o plano. Isto certamente levaria a um modelo com problemas de generalização, visto que quase certamente um cliente de renda média sempre seria classificado como não cancelado, ainda que no futuro possa haver algum cliente de renda média que por ventura cancele o plano. Para além disso, esta informação certamente distorceria os parâmetros dos modelos, inclusive podendo levar modelos mais sensíveis à separação perfeita — como a regressão logística — a ter problemas de convergência. Como a remoção destas observações ainda preserva um volume de dados extremamente satisfatório, julgo ser seguro simplesmente optar por não inseri-los no modelo.
Outras informações identificadas como potencialmente não relevantes na etapa exploratória serão mantidas nesta etapa, podendo ser removidas na comparação de modelos posteriormente.
Diversos modelos podem ser escolhidos para a tarefa de classificação binária. Naive Bayes, regressão logística, árvores de decisão, florestas aleatórias, árvores com bagging, XGBoost, Gradient Boost e demais modelos. Além disso, é crucial realizar o fine tuning dos parâmetros de cada modelo, visto que cada um deles contém diversos hiperparâmetros, e a combinação ótima em geral só pode ser encontrada por força bruta. Diversas estratégias podem ser pensadas para teste de hiperparâmetros, como um grid plano, um quadrado latino, uma busca aleatória, varreduras bayesianas, etc. Em geral, opta-se pelo método mais simples — a busca plana — e testa-se métodos mais sofisticados caso hiperparâmetros ideais não sejam encontrados, ou se houver problema de tempo de execução das buscas no grid.
A validação é uma etapa crucial na modelagem. Os modelos sempre buscarão melhor ajuste possível aos dados, entretanto este ajuste pode significar a compreensão perfeita dos dados que forem a eles fornecidos, porém na avaliação de um dado futuro posterior, este modelo pode incorrer em erros em função de sobreajuste (overfitting), isto é, o modelo aprende exatamente os padrões dos dados que foram fornecidos, mas é incapaz de generalizar os resultados para novas observações. Para isso, uma das estratégias é separar o conjunto de dados em treino e teste, em geral utilizando 80% dos dados para treino e 20% dos dados para teste. Desta forma, as métricas do modelo serão avaliadas no conjunto de testes, conjunto este não utilizado para ajuste do modelo, para verificar o quão bem o modelo compreende padrões para além de decorar os dados que a ele foram fornecidos.
A validação cruzada é uma extensão desta ideia. Não iremos apenas ajustar os modelos, mas também selecionar as melhores combinações possíveis de hiperparâmetros deles. Para isso, podemos dividir o conjunto de dados em treino, teste e validação. Porém, quanto mais separações fazemos, menos dados temos para treino, e prescindir de uma boa quantidade destes pode não ser viável em algumas situações. Para isso, esta metodologia fragmenta o conjunto de treino em v segmentos (v-folds), utilizando uma parte desta para avaliação de hiperparâmetro durante o ajuste do modelo, e as 4 partes restantes para teste. Além disso, a implementação embaralha e troca a ordem desses segmentos a cada ajuste, garantindo a confiabilidade das métricas produzidas.
Desta forma, podemos avaliar o modelo, testar conjuntos de hiperparâmetros e testar a performance do modelo utilizando uma abordagem segura, confiável e crível.
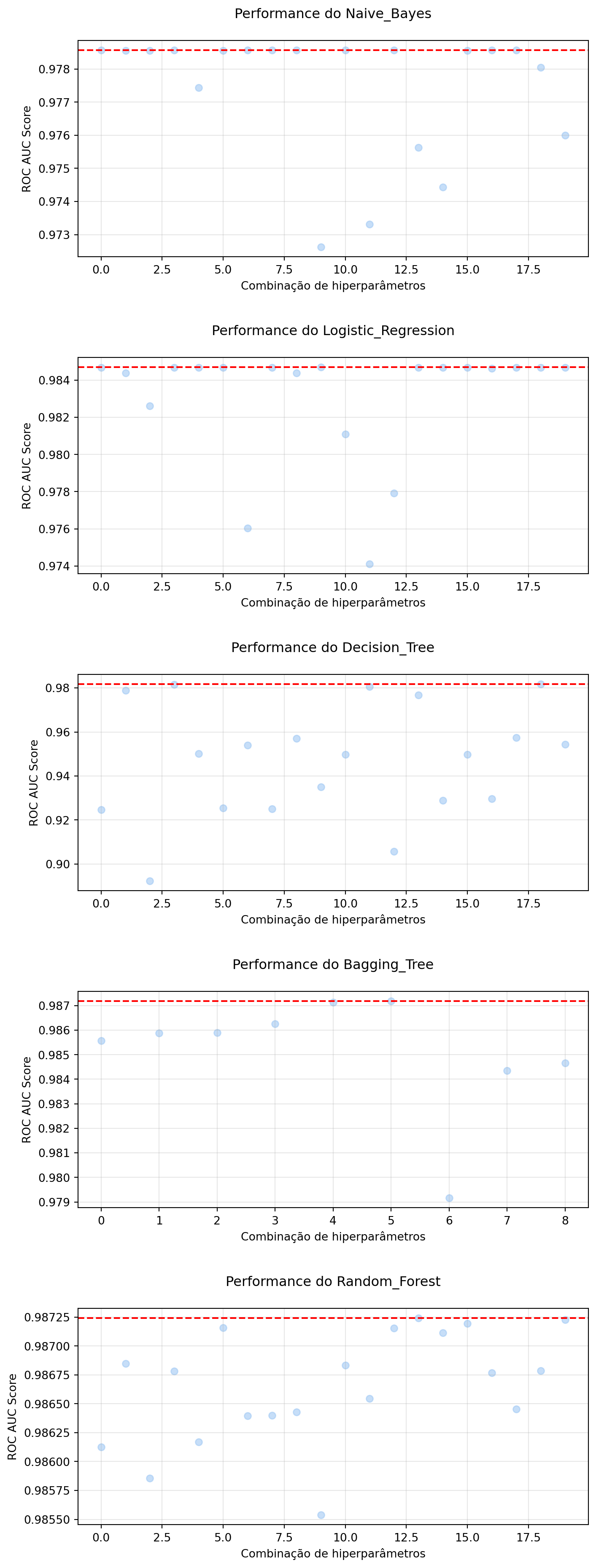
O Quadro acima mostra as principais métricas associadas aos modelos testados. Nota-se que todos os modelos performaram relativamente bem em todas as métricas selecionadas, com destaque para a área sob a curva (ROC AUC). Isto indica que qualquer um dos modelos poderia ser utilizado para previsão, com F1-Score acima de 95%, que em geral é a métrica mais importante para avaliação de churn.
Os gráficos acima demonstram a necessidade de realizar o tuning de hiperparâmetros. Notamos que a performance de todos os modelos oscilam a depender da combinação de hiperparâmetros utilizada. Estaremos especialmente interessados nos modelos cuja combinação de hiperparâmetros foi a melhor possível, segundo alguma métrica selecionada.
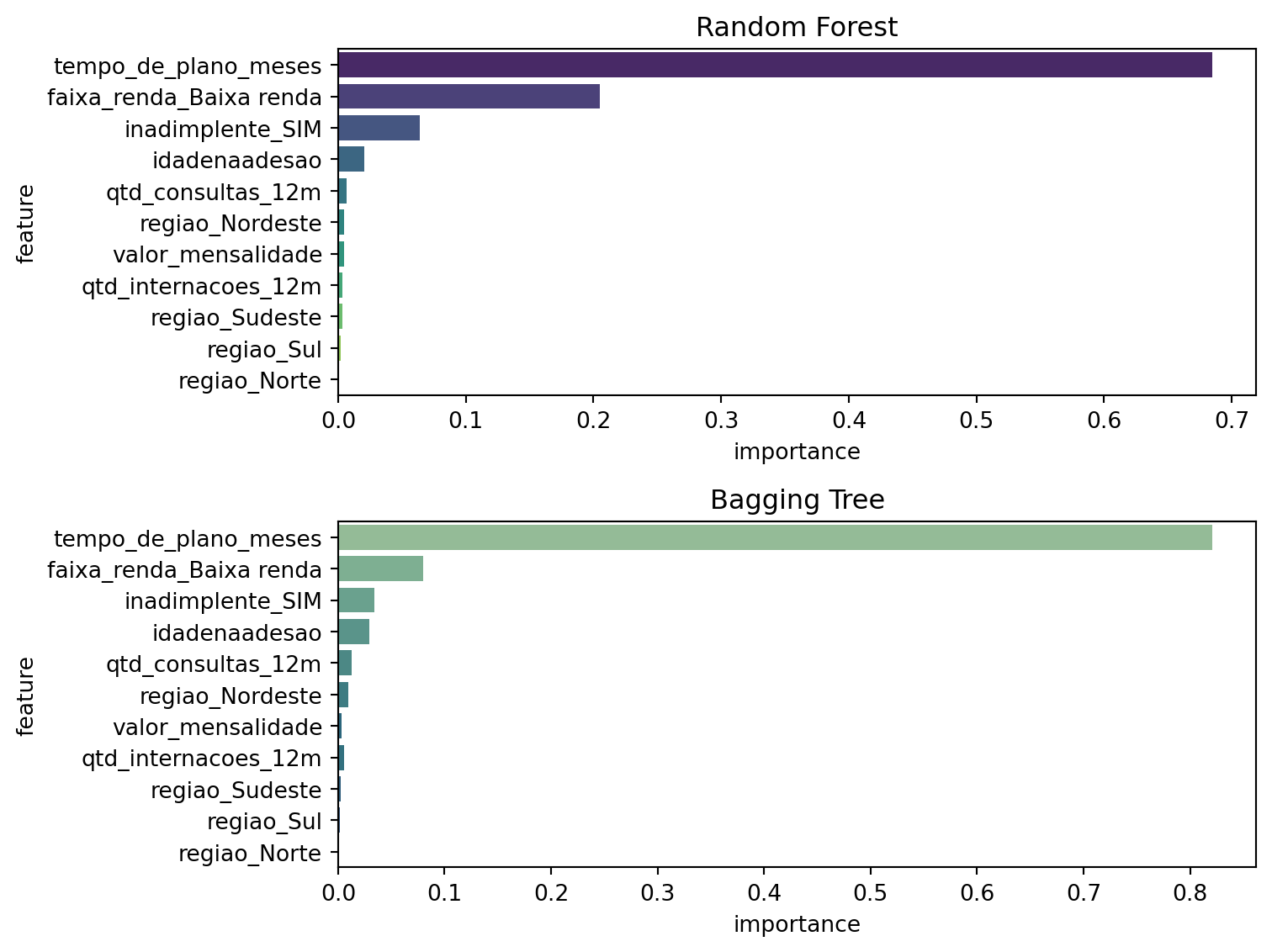
A Figura acima mostra as features mais importantes nos modelos que melhor perfomaram — bagging tree e random forest. Da Figura, podemos inferir que o fator mais importante para explicar o churn de clientes é o tempo de permanência no plano, em que clientes mais antigos são muito menos propensos a cancelar. Além disso, pode-se dizer que a renda também é característica importante, em que clientes de baixa renda são mais propensos a cancelar o plano em relação a categoria de referência (clientes de alta renda). Outros fatores foram menos relevantes, mas ainda podem ser considerados — como a inadimplência. Com qualquer um destes modelos, estamos munidos de poderosa ferramenta para prever o churn de um cliente, bem como ter alguma noção dos fatores mais importantes na determinação deste cenário. Em especial o modelo de random forest que, por ter obtido as melhores métricas ante aos outros testados, será o modelo escolhido e utilizado para previsão.
Problemáticas desta abordagem
Em geral estamos diante de um dos seguintes cenários no contexto da ciência de dados: previsão ou explicabilidade de fatores para áreas não técnicas. Busca-se dentre as opções o modelo com melhores métricas preditivas, como os modelos apresentados anteriormente. Porém, estes modelos costumam perder explicabilidade proporcionalmente com a sua capacidade preditiva. E isto pode ser um problema, pois dificulta a comunicação dos resultados, e a elaboração de ações para reversão de cenários apresentados pelo modelo. No caso concreto, temos interesse na reversão da alta taxa de churn, e queremos saber que tipo de atitudes e ações podemos adotar para a reversão deste cenário, bem como, se possível, metrificar o impacto de cada um dos fatores para traçarmos as principais estratégias, utilizando por exemplo uma matriz SWOT. Estes modelos indicam parcialmente a direção dos esforços, mas a metrificação exata dessa importância mostra-se bastante complicada. Além disso, foram ignoradas algumas conclusões parciais da etapa de análise exploratória, como a inclusão de covariáveis que aparentemente não eram significativamente diferentes entre os grupos que cancelaram e que não cancelaram o plano. Nota-se sobretudo o domínio da covariável relativa ao tempo de plano do cliente, que certamente é significativa, mas não é o único fator que pode ser acompanhado para elaboração de ações estratégicas.
Solução
Desta forma, uma abordagem que pode e deve ser adotada é a construção de um modelo auxiliar. Os modelos anteriores são excelentes para previsão, e poderão ser utilizados para este propósito. Entretanto, a construção de um modelo com maior parcimônia e lastro com a análise exploratória se faz necessária para extrair interpretação direta de coeficientes do modelo, tornando possível uma comunicação mais assertiva com a área administrativa sobre os impactos e a magnitude destes na análise de churn, possibilitando assim a formulação de estratégias eficientes para reversão deste cenário.
O modelo interpretável
Para a tarefa de classificação binária, um modelo especialmente interessante para interpretação de coeficientes é a regressão logística. Isto por que, por utilizar uma função de ligação logito e ter pressuposto de linearidade nos parâmetros, caso se ajuste bem, pode ser interpretado de seus coeficientes o aumento ou diminuição da chance de cancelamento do plano. Desta forma, poderemos quantificar não só quais fatores são mais importantes, mas o quão mais importantes são no cálculo dessa chance.
Para obter resultados coerentes, camadas adicionais de pré processamento serão realizadas para ajuste deste modelo. A regressão logística apresenta graves problemas em casos de separação perfeita dos dados, por conta da função logito. Nestes casos, os coeficientes “explodem” e perdem a interpretabilidade, ainda que o modelo esteja com métricas de previsão boas. Como a intenção deste modelo é a interpretação dos parâmetros (se preservadas métricas de ajuste aceitáveis), etapas adicionais de engenharia de features são necessárias, e serão descritas a seguir:
A covariável tempo de plano em meses será categorizada, transformada em 4 categorias segundo seus quantis. Isto irá evitar a separação perfeita dos dados;
Como revelado na etapa exploratória, as covariáveis renda e inadimplência são melhor interpretadas se analisadas conjuntamente. Desta forma, será criada uma nova variável, que é a combinação entre os fatores destas duas, para melhor demonstrar este efeito;
Demais covariáveis indicadas como pouco significativas na etapa de análise exploratória serão desconsideradas.
Desta forma, iremos ajustar o modelo explicando o cancelamento baseado em categorias da nova feature tempo de plano, inadimplência combinada com renda e região (agrupamento de unidades da federação segundo classificação do IBGE).
O principal objetivo deste modelo será a extração de interpretação dos parâmetros. Como ajustou-se um modelo mais parcimonioso, é esperado que suas métricas sejam inferiores ao modelo saturado ajustado anteriormente. Isto é, para previsão, os modelos anteriores são ligeiramente melhores do que o modelo ajustado nesta etapa. Isso não significa que o modelo possa ser ruim: suas métricas devem ainda ser satisfatórias.
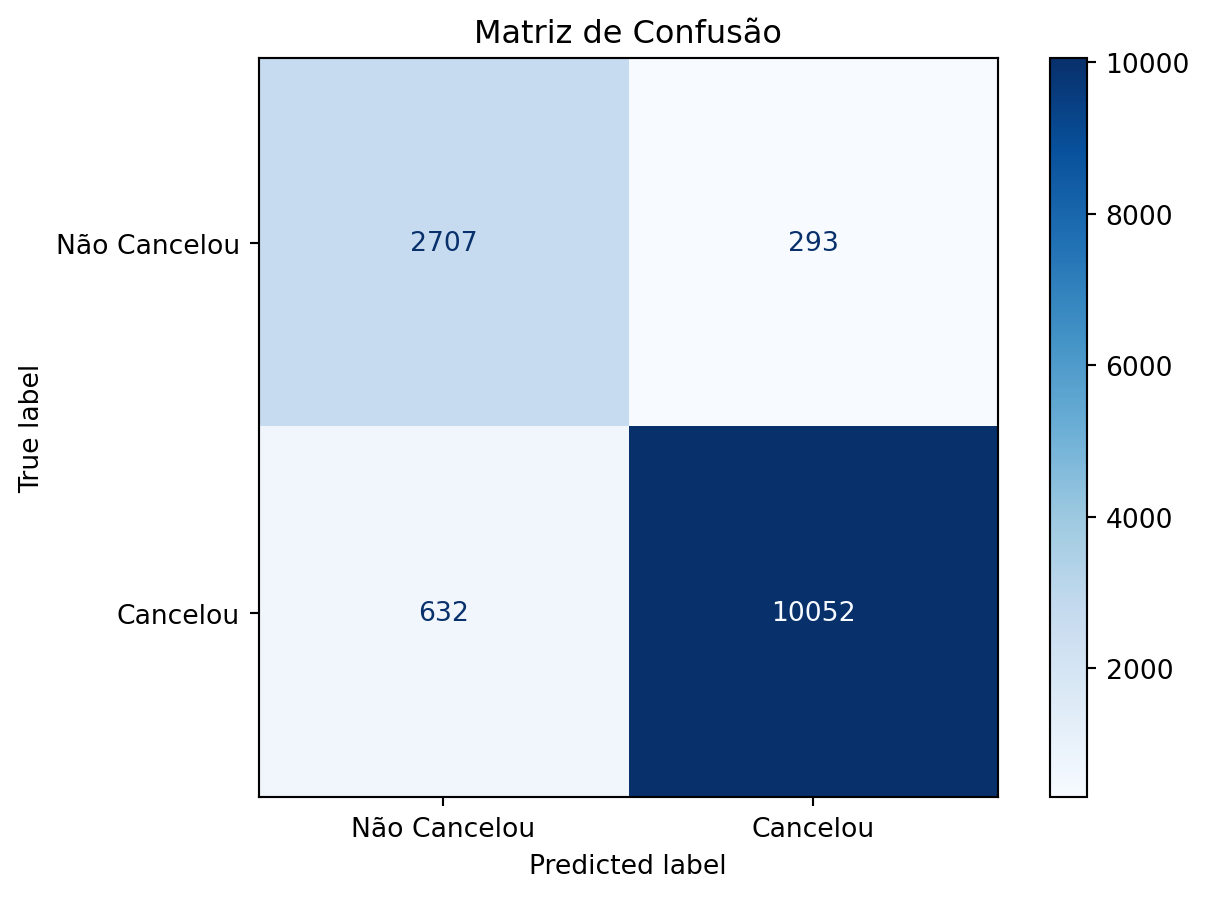
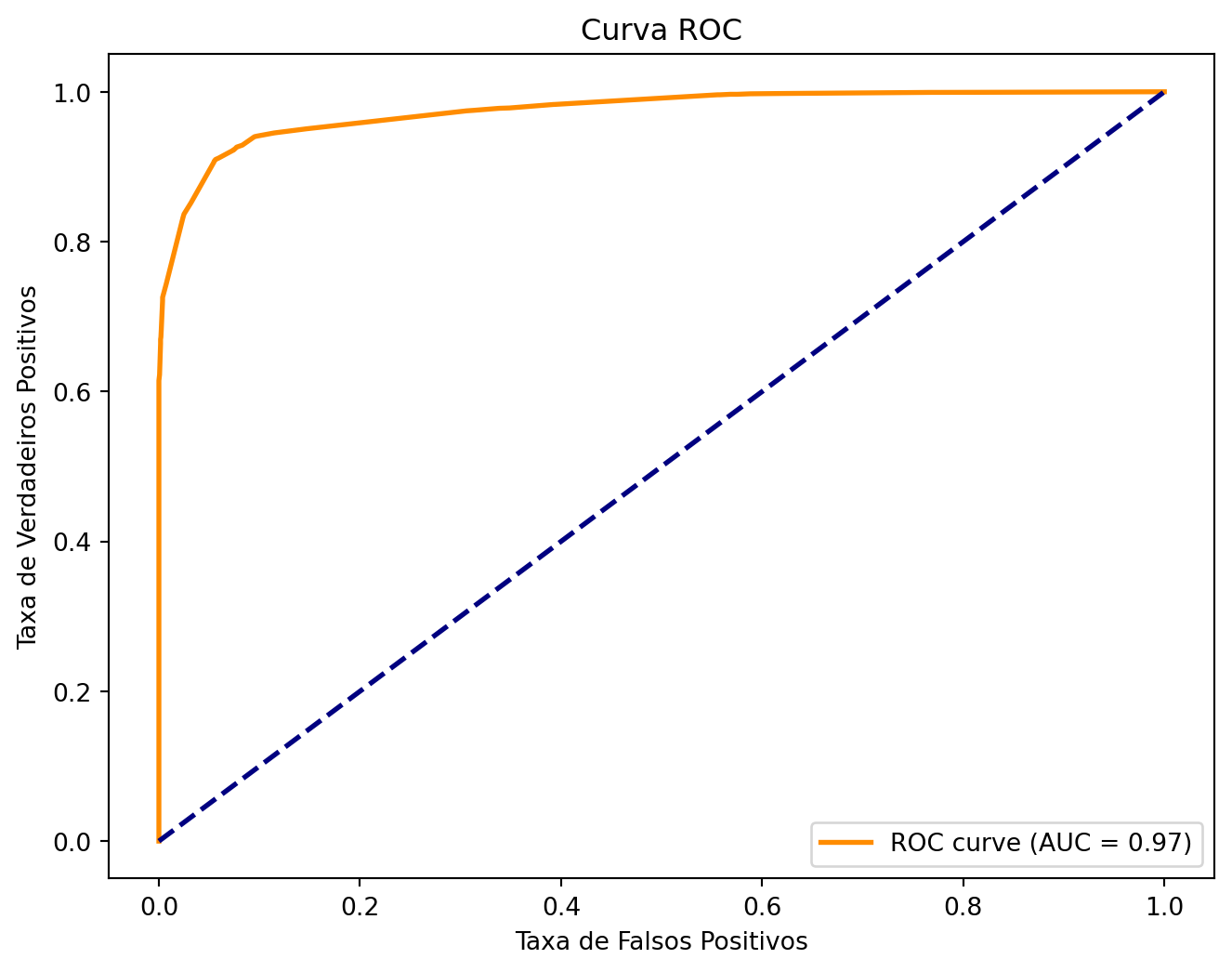
Conforme observado na análise de diagnóstico acima, como valores das principais métricas, área sob a curva e matriz de confusão, notamos uma ligeira piora de algumas métricas em relação ao modelo saturado, em especial na precisão de classificação de verdadeiros negativos. Entretanto, observando o conjunto das métricas em geral, pode-se dizer que este modelo se ajustou bem aos dados, em especial observando as métricas de F1-Score e área sob a curva — ambas performando acima de 95% — que são essenciais neste contexto.
Desta forma, podemos ter segurança na interpretação dos parâmetros deste modelo, e comunicação de seus resultados para as outras áreas da empresa
Mostrar o código
logreg = model.named_steps['classifier']X_trans = model.named_steps['preprocessor'].transform(X_train)try: pred_probs = logreg.predict_proba(X_trans) sample_weights = pred_probs[:, 1] * (1- pred_probs[:, 1]) X_design = np.hstack([np.ones((X_trans.shape[0], 1)), X_trans]) weighted_X = sample_weights[:, np.newaxis] * X_design cov_matrix = np.linalg.inv(safe_sparse_dot(X_design.T, weighted_X))exceptExceptionas e:print(f"Erro no cálculo da matriz de covariância: {e}") n_features = X_trans.shape[1] cov_matrix = np.eye(n_features +1) *0.01se = np.sqrt(np.diag(cov_matrix))[1:] if cov_matrix isnotNoneelse np.zeros(X_trans.shape[1])z_scores = logreg.coef_[0] / sep_values = stats.norm.sf(np.abs(z_scores)) *2bin_edges = model.named_steps['preprocessor'].named_transformers_['tempo_plano'].named_steps['binning'].bin_edges_[0]feature_map = {'tempo_plano_bin_1': f"Tempo: {bin_edges[1]:.0f}-{bin_edges[2]:.0f} meses",'tempo_plano_bin_2': f"Tempo: {bin_edges[2]:.0f}-{bin_edges[3]:.0f} meses",'tempo_plano_bin_3': f"Tempo: >{bin_edges[3]:.0f} meses",'renda_alta_inadimplente_sim': "Alta renda + Inadimplente",'renda_baixa_inadimplente_nao': "Baixa renda + Não inadimplente",'renda_baixa_inadimplente_sim': "Baixa renda + Inadimplente",'regiao_Norte': "Região Norte",'regiao_Nordeste': "Região Nordeste",'regiao_Sudeste': "Região Sudeste",'regiao_Sul': "Região Sul"}results_df = pd.DataFrame({'Variável': [feature_map.get(f, f) for f in feature_names],'Coeficiente': logreg.coef_[0],'Erro Padrão': se,'z-value': z_scores,'p-value': ['<0.0001'if p <0.0001elsef'{p:.4f}'for p in p_values],'Odds Ratio': np.round(np.exp(logreg.coef_[0]), 4)})results_df = results_df.reindex(logreg.coef_[0].argsort()[::-1]).reset_index(drop=True)print(results_df.to_string(index=False, float_format=lambda x: f"{x:.4f}"))
Variável Coeficiente Erro Padrão z-value p-value Odds Ratio
Baixa renda + Inadimplente 4.8816 0.0801 60.9565 <0.0001 131.8379
Baixa renda + Não inadimplente 2.9060 0.0608 47.7791 <0.0001 18.2839
Tempo: 205-253 meses 1.9264 0.7675 2.5101 0.0121 6.8648
Alta renda + Inadimplente 1.7975 0.1147 15.6764 <0.0001 6.0344
Região Sul 0.7726 0.0863 8.9543 <0.0001 2.1654
Região Sudeste 0.5548 0.0656 8.4537 <0.0001 1.7416
Região Norte 0.2458 0.1386 1.7728 0.0763 1.2786
Região Nordeste -0.1179 0.0669 -1.7632 0.0779 0.8888
Tempo: 253-291 meses -4.6209 0.2655 -17.4069 <0.0001 0.0098
Tempo: >291 meses -7.9566 0.2653 -29.9950 <0.0001 0.0004
Resultados do modelo e interpretação
A utilização do p-valor inferior a 0,05 é uma convenção útil na estatística, especialmente para estudos com amostras pequenas. Neste caso, visto a grande massa de dados, será considerado significante apenas coeficientes com p-valor inferior a 0,0001 — critério mais apropriado para este volume de dados –, isto é, significantes sob qualquer nível de confiança.
Fixada a categoria de referência: Clientes de alta renda não inadimplentes, moradores do centro-oeste e com tempo de plano até 205 meses, podemos ver como a alteração de um destes fatores — mantidos os restantes inalterados — impacta na chance de cancelamento do plano.
Dos fatores que aumentam a chance de cancelamento, destaca-se que clientes de baixa renda e inadimplentes apresentam chance de cancelamento 131 vezes superior em relação a categoria de referência. Recomenda-se prioridade para este recorte nas ações estratégicas para permanência no plano. Clientes de baixa renda não inadimplentes também apresentam chance de cancelamento 18 vezes superior aos clientes da categoria de referência. Isto indica que uma ação com vista na permanência para clientes de baixa renda, independente de inadimplência, pode ser crucial para reversão da alta taxa de churn. Ainda assim, a inadimplência é um fator relevante, pois clientes de alta renda inadimplentes apresentam uma chance superior a 6 vezes à chance de cancelamento do plano de clientes de alta renda adimplentes, o que indica que a reversão da inadimplência pode ser importante para permanência de clientes com este recorte de renda. Quanto a diferenças regionais, clientes das regiões Sul apresentam o dobro de chance de cancelamento — e 74% maior chance para clientes da região Sudeste —, indicando que políticas regionalizadas podem ser relevantes para reversão da alta taxa de churn nesas regiões.
O fator que diminui a chance de cancelamento é o tempo de permanência no plano. Clientes com permanência no plano entre 253 e 291 meses apresentam menos de 1% da chance de cancelamento dos clientes da categoria de referência, enquanto clientes com tempo de permanência superior a 291 meses apresentam chance de cancelamento de apenas 0,04% em relação aos clientes da categoria de referência, indicando que ações de permanência no plano por mais tempo podem levar a um cenário em que menos clientes cancelem o plano por já serem clientes muito antigos.
Resultados
A modelagem de dados confirma as tendências observadas na análise exploratória de dados. De fato, clientes com maior tempo de permanência no plano são muito menos propensos a cancelar. Esta é a informação considerada mais importante por todos os modelos analisados. A inadimplência do cliente, quando combinada a sua renda, também constitui um fator altamente explicativo, em que clientes inadimplentes tendem a cancelar mais o plano, em especial os clientes de baixa renda. Existe ainda um fator regional para algumas regiões, posto que clientes das regiões sul e sudeste têm mais propensão a cancelar o plano.
Todos os modelos selecionados performaram bem. Para análise preditiva, o modelo de random forest saturado é ligeiramente melhor que o modelo logístico, sendo portanto mais indicado para prever o risco de cancelamento de clientes. Com acurácia de 94,68%, esperamos que a grande massa de suas previsões estejam de acordo com o valor esperado na realidade.
Por outro lado, o modelo logístico obteve também resultados satisfatórios, sendo portanto seguro interpretar seus parâmetros com objetivo de extrair insights relevantes para formulação de estratégias de negócio direcionadas para perfis de cliente específicos. Com acurácia de 93,2%, em especial para clientes que não cancelaram o plano, temos segurança suficiente da lastreabilidade de seus parâmetros na realidade.
Conclusão
Conforme especificado, o objetivo desta análise é estimar quais beneficiários têm maior risco de evasão nos próximos 12 meses, dado um modelo estatístico preditivo. Desta forma, podemos utilizar o modelo de random forest para realizar esta estimação.
Distribuição de clientes por faixa de risco de cancelamento:
Mostrar o código
rf_model = results['Random_Forest']['best_model']probas = rf_model.predict_proba(X)[:, 1]faixas = pd.cut( probas, bins=[0, .1, .25, 0.5, 0.75, 0.9, 1.0], labels=['Risco até 10%','Risco entre 10% e 25%','Risco entre 25% e 50%','Risco entre 50% e 75%','Risco entre 70% e 90%','Risco superior a 90%' ], include_lowest=True)contagem_por_faixa = faixas.value_counts().sort_index()risco_df = pd.DataFrame({'Faixa de Risco': ['Até 10%','10% - 25%', '25% - 50%','50% - 75%','75% - 90%','Acima de 90%' ],'Clientes': contagem_por_faixa.values})risco_df['Clientes'] = risco_df['Clientes'].apply(lambda x: f"{x:,.0f}".replace(",", "."))display(risco_df)
Faixa de Risco
Clientes
0
Até 10%
7.033
1
10% - 25%
3.668
2
25% - 50%
5.134
3
50% - 75%
2.834
4
75% - 90%
2.164
5
Acima de 90%
47.585
Note que isto se refere aos clientes que foram de fato inseridos no modelo (seja para treino, seja para teste). Deve-se observar que existem ainda 22.356 clientes removidos do modelo, não descritos na tabela acima, por serem classificados como renda média. Para estes clientes, como não houve cancelamento algum, pode-se dizer que o risco de cancelamento é zero ou próximo de zero.
Pode-se inferir ainda, dos resultados do modelo logístico, que os clientes com maior risco de cancelamento são clientes de baixa renda, inadimplentes ou não, com baixo tempo de permanência no plano.
Destas informações, nota-se que o produto oferecido pela empresa parece ser adequado, entretanto pode existir uma falta de alinhamento com as características de alguns grupos de clientes. Recomenda-se então ajustes no produto no sentido de melhor abarcar perfis diversos de clientes.
Algumas ações estratégicas que podem ser sugeridas são:
Desconto regressivo para os clientes. Apesar do valor da mensalidade não ser significativo, o desconto regressivo poderia contribuir indiretamente para maior permanência no plano, em especial até 290 meses (pouco mais de 24 anos) de adesão — valor crítico no qual a chance do cliente evadir do plano se torna quase nula.
Revisão da política de inadimplência. Como a chance do cliente inadimplente cancelar o plano é extremamente significativa, em especial para clientes de baixa renda, recomenda-se, por exemplo, oferecer planos de pagamento facilitados para clientes de baixa renda, bem como revisão da política de cobrança para primeiras inadimplências, como também campanhas educativas e lembretes de pagamento para os clientes, em especial os de alta renda, antes de proceder para a inadimplência.
Avaliação da estrutura regional nos estados do sudeste e sul do país, como rede conveniada e estudo de concorrentes regionais.
Para avaliação dessas estratégias, recomenda-se a implementação de um programa piloto com uma pequena quantidade de clientes em faixas de risco de cancelamento superior a 50% para posterior avaliação de efetividade dessas ações, utilizando técnicas como testes A/B ou inferência causal antes da implementação da ação na rede conveniada inteira.