Mostrar códigos
!pip install optunaRedes Neurais Profundas | Prof. Dr. Guilherme Souza Rodrigues
Para esta lista, utilizei o kernel do Colab no VSCode, para poder aproveitar do poder computacional de uma GPU, que não tenho no meu notebook
O Colab já tem quase todos os pacotes que necessito instalado, faltando apenas o optuna:
!pip install optunaCarregando as bibliotecas
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import optuna
import numpy as np
import random
import matplotlib.pyplot as plt
import seaborn as sns
import copyComo utilizei o kernel Colab, é muito mais simples hospedar os dados na nuvem, para que ele consiga buscá-los e ler diretamente.
df = pd.read_csv('https://raw.githubusercontent.com/penasta/rna1/refs/heads/main/dados/dados.csv')OBS: gerei estes dados no R, utilizando a seed sugerida pelo professor, para garantir a confiabilidade dos resultados.
O código para geração de dados idênticos se encontram neste link
Fazendo a separação treino-teste-validação como nas últimas listas, para comparabilidade
X = df[['x1.obs', 'x2.obs']].to_numpy().T
Y = df[['y']].to_numpy().T
x_treino = X[:, 0:8000]
x_val = X[:, 8000:9000]
x_teste = X[:, 9000:10000]
y_treino = Y[:, 0:8000]
y_val = Y[:, 8000:9000]
y_teste = Y[:, 9000:10000]Verificando os formatos
print("X:", X.shape)
print("Y:", Y.shape)
print("Treino:", x_treino.shape, y_treino.shape)
print("Validação:", x_val.shape, y_val.shape)
print("Teste:", x_teste.shape, y_teste.shape)X: (2, 100000)
Y: (1, 100000)
Treino: (2, 8000) (1, 8000)
Validação: (2, 1000) (1, 1000)
Teste: (2, 1000) (1, 1000)x_treino_t = torch.tensor(x_treino.T, dtype=torch.float32)
y_treino_t = torch.tensor(y_treino.T, dtype=torch.float32).view(-1,1)
x_val_t = torch.tensor(x_val.T, dtype=torch.float32)
y_val_t = torch.tensor(y_val.T, dtype=torch.float32).view(-1,1)class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(2, 2)
self.out = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
nn.init.zeros_(self.hidden.weight)
nn.init.zeros_(self.hidden.bias)
nn.init.zeros_(self.out.weight)
nn.init.zeros_(self.out.bias)
def forward(self, x):
h = self.sigmoid(self.hidden(x))
y_hat = self.out(h)
return y_hatPhi = SimpleNN()
criterion = nn.MSELoss()
optimizer = optim.SGD(Phi.parameters(), lr=0.1)
epochs = 100
losses_treino = []
losses_val = []
best_val_loss = np.inf
best_state = None
best_epoch = 0for epoch in range(epochs):
optimizer.zero_grad()
y_pred = Phi(x_treino_t)
train_loss = criterion(y_pred, y_treino_t)
train_loss.backward()
optimizer.step()
with torch.no_grad():
val_pred = Phi(x_val_t)
val_loss = criterion(val_pred, y_val_t)
losses_treino.append(train_loss.item())
losses_val.append(val_loss.item())
if val_loss.item() < best_val_loss:
best_val_loss = val_loss.item()
best_state = {k: v.clone() for k, v in Phi.state_dict().items()}
best_epoch = epoch + 1print(f"Melhor época (validação): {best_epoch}")
print(f"Melhor MSE de validação: {best_val_loss:.6f}")Melhor época (validação): 100
Melhor MSE de validação: 97.893570Estes resultados estranhamente diferem do gabarito, mas batem com os resultados que eu encontrei na lista 2. Então, se fiz algo errado lá, fiz exatamente igual nesta lista, pois bateram os resultados tanto no R como no Python; tornando os modelos comparáveis de alguma forma
Configurações iniciais
SEED = 22025
torch.manual_seed(SEED)
np.random.seed(SEED)
random.seed(SEED)
n_optuna = 100
learning_rate = 0.001
qtd_epocas = 200
paciencia = 20
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device:", device)Device: cudaPreparando os dados para o Torch
def make_loaders(X_train, y_train, X_val, y_val, X_test, y_test, device):
X_train_t = torch.tensor(X_train.T, dtype=torch.float32).to(device)
y_train_t = torch.tensor(y_train.T, dtype=torch.float32).view(-1, 1).to(device)
X_val_t = torch.tensor(X_val.T, dtype=torch.float32).to(device)
y_val_t = torch.tensor(y_val.T, dtype=torch.float32).view(-1, 1).to(device)
X_test_t = torch.tensor(X_test.T, dtype=torch.float32).to(device)
y_test_t = torch.tensor(y_test.T, dtype=torch.float32).to(device).view(-1, 1)
train_loader = DataLoader(TensorDataset(X_train_t, y_train_t), batch_size=32, shuffle=True)
val_loader = DataLoader(TensorDataset(X_val_t, y_val_t), batch_size=64, shuffle=False)
test_loader = DataLoader(TensorDataset(X_test_t, y_test_t), batch_size=64)
return train_loader, val_loader, test_loadertrain_loader, val_loader, test_loader = make_loaders(x_treino, y_treino, x_val, y_val, x_teste, y_teste, device)Construindo a rede neural
def build_model(input_dim, hidden_layers, activation_name="relu", dropout=0.0):
layers = []
act = {
"relu": nn.ReLU()
}[activation_name]
prev_dim = input_dim
for h in hidden_layers:
layers.append(nn.Linear(prev_dim, h))
layers.append(act)
if dropout > 0:
layers.append(nn.Dropout(dropout))
prev_dim = h
layers.append(nn.Linear(prev_dim, 1))
return nn.Sequential(*layers).to(device)Definindo função objetivo do optuna para otimização de hiperparâmetros da rede
def objective(trial, train_loader, val_loader, input_dim):
n_layers = trial.suggest_int("n_layers", 2, 6)
hidden = [
trial.suggest_int(f"n_units_layer_{i}", 8, 256, log=True)
for i in range(n_layers)
]
dropout = trial.suggest_float("dropout", 0.0, 0.5)
weight_decay = trial.suggest_float("weight_decay", 1e-6, 1e-2, log=True)
lr = trial.suggest_float("lr", 3e-5, 3e-3, log=True)
model = build_model(
input_dim=input_dim,
hidden_layers=hidden,
activation_name="relu",
dropout=dropout
).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.MSELoss()
best_val = float("inf")
patience = paciencia
patience_count = 0
for epoch in range(qtd_epocas):
model.train()
for xb, yb in train_loader:
optimizer.zero_grad()
pred = model(xb)
loss = criterion(pred, yb)
loss.backward()
optimizer.step()
model.eval()
val_losses = []
with torch.no_grad():
for xb, yb in val_loader:
pred = model(xb)
val_losses.append(criterion(pred, yb).item())
val_mse = np.mean(val_losses)
if epoch % 5 == 0:
trial.report(val_mse, epoch)
if trial.should_prune():
raise optuna.TrialPruned()
if val_mse < best_val:
best_val = val_mse
patience_count = 0
else:
patience_count += 1
if patience_count >= patience:
break
return best_valOtimizando
pruner = optuna.pruners.HyperbandPruner()
study = optuna.create_study(direction="minimize", pruner=pruner)
study.optimize(lambda trial: objective(trial, train_loader, val_loader, input_dim=x_treino.shape[0]),
n_trials=n_optuna,
show_progress_bar=True)
print("Melhores hiperparâmetros:")
print(study.best_trial.params)[I 2025-11-23 02:37:22,613] Trial 0 finished with value: 111.23853206634521 and parameters: {'n_layers': 6, 'n_units_layer_0': 163, 'n_units_layer_1': 126, 'n_units_layer_2': 9, 'n_units_layer_3': 22, 'n_units_layer_4': 43, 'n_units_layer_5': 14, 'dropout': 0.47935819802454194, 'weight_decay': 0.00018693781661057758, 'lr': 0.0007753603589791862}. Best is trial 0 with value: 111.23853206634521.
[I 2025-11-23 02:38:10,057] Trial 1 finished with value: 4.869601458311081 and parameters: {'n_layers': 3, 'n_units_layer_0': 65, 'n_units_layer_1': 82, 'n_units_layer_2': 15, 'dropout': 0.3022739617633364, 'weight_decay': 4.037145961447963e-06, 'lr': 0.001741569496790645}. Best is trial 1 with value: 4.869601458311081.
[I 2025-11-23 02:38:49,427] Trial 2 finished with value: 107.1932954788208 and parameters: {'n_layers': 6, 'n_units_layer_0': 131, 'n_units_layer_1': 9, 'n_units_layer_2': 87, 'n_units_layer_3': 10, 'n_units_layer_4': 23, 'n_units_layer_5': 23, 'dropout': 0.37498906325856457, 'weight_decay': 7.0850285475096515e-06, 'lr': 0.0002478855862293691}. Best is trial 1 with value: 4.869601458311081.
[I 2025-11-23 02:39:20,456] Trial 3 finished with value: 38.14531660079956 and parameters: {'n_layers': 5, 'n_units_layer_0': 165, 'n_units_layer_1': 111, 'n_units_layer_2': 70, 'n_units_layer_3': 219, 'n_units_layer_4': 24, 'dropout': 0.35781133019694217, 'weight_decay': 5.249253216117566e-06, 'lr': 5.541752218708039e-05}. Best is trial 1 with value: 4.869601458311081.
[I 2025-11-23 02:41:06,224] Trial 4 finished with value: 2.596485123038292 and parameters: {'n_layers': 3, 'n_units_layer_0': 82, 'n_units_layer_1': 169, 'n_units_layer_2': 8, 'dropout': 0.06765427372525029, 'weight_decay': 0.0008751609313247975, 'lr': 0.0001598064820033447}. Best is trial 4 with value: 2.596485123038292.
[I 2025-11-23 02:41:22,459] Trial 5 pruned.
[I 2025-11-23 02:41:25,892] Trial 6 pruned.
[I 2025-11-23 02:41:29,007] Trial 7 pruned.
[I 2025-11-23 02:41:32,483] Trial 8 pruned.
[I 2025-11-23 02:41:35,897] Trial 9 pruned.
[I 2025-11-23 02:43:08,149] Trial 10 finished with value: 17.7527534365654 and parameters: {'n_layers': 2, 'n_units_layer_0': 8, 'n_units_layer_1': 36, 'dropout': 0.005403369820202418, 'weight_decay': 0.006547138786729971, 'lr': 7.89405422559481e-05}. Best is trial 4 with value: 2.596485123038292.
[I 2025-11-23 02:43:11,197] Trial 11 pruned.
[I 2025-11-23 02:43:27,809] Trial 12 pruned.
[I 2025-11-23 02:44:19,009] Trial 13 finished with value: 2.7238475680351257 and parameters: {'n_layers': 3, 'n_units_layer_0': 79, 'n_units_layer_1': 96, 'n_units_layer_2': 8, 'dropout': 0.16370140642840897, 'weight_decay': 0.00014447326129793473, 'lr': 0.0029222255741136395}. Best is trial 4 with value: 2.596485123038292.
[I 2025-11-23 02:45:51,564] Trial 14 finished with value: 2.2709049582481384 and parameters: {'n_layers': 2, 'n_units_layer_0': 236, 'n_units_layer_1': 143, 'dropout': 0.15377776987848676, 'weight_decay': 0.00016684830410356572, 'lr': 0.00015339988551505348}. Best is trial 14 with value: 2.2709049582481384.
[I 2025-11-23 02:47:24,469] Trial 15 finished with value: 2.3764026388525963 and parameters: {'n_layers': 2, 'n_units_layer_0': 224, 'n_units_layer_1': 158, 'dropout': 0.06050916285930005, 'weight_decay': 0.0009208984024629657, 'lr': 0.00014494167312875133}. Best is trial 14 with value: 2.2709049582481384.
[I 2025-11-23 02:47:27,185] Trial 16 pruned.
[I 2025-11-23 02:47:29,885] Trial 17 pruned.
[I 2025-11-23 02:47:37,362] Trial 18 pruned.
[I 2025-11-23 02:48:17,025] Trial 19 pruned.
[I 2025-11-23 02:48:21,137] Trial 20 pruned.
[I 2025-11-23 02:48:23,955] Trial 21 pruned.
[I 2025-11-23 02:49:35,713] Trial 22 finished with value: 1.4792074039578438 and parameters: {'n_layers': 3, 'n_units_layer_0': 224, 'n_units_layer_1': 177, 'n_units_layer_2': 33, 'dropout': 0.07844299817724425, 'weight_decay': 0.0003862755598758188, 'lr': 0.00019045099531338352}. Best is trial 22 with value: 1.4792074039578438.
[I 2025-11-23 02:49:38,380] Trial 23 pruned.
[I 2025-11-23 02:50:53,729] Trial 24 finished with value: 1.3409594930708408 and parameters: {'n_layers': 3, 'n_units_layer_0': 243, 'n_units_layer_1': 251, 'n_units_layer_2': 35, 'dropout': 0.04011653320717895, 'weight_decay': 0.00034386489157846496, 'lr': 0.0002111064977308286}. Best is trial 24 with value: 1.3409594930708408.
[I 2025-11-23 02:52:01,205] Trial 25 finished with value: 1.1774947792291641 and parameters: {'n_layers': 4, 'n_units_layer_0': 141, 'n_units_layer_1': 250, 'n_units_layer_2': 36, 'n_units_layer_3': 66, 'dropout': 0.007299638573311257, 'weight_decay': 4.123901877439077e-05, 'lr': 0.00022634758488239846}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:52:52,259] Trial 26 pruned.
[I 2025-11-23 02:53:34,900] Trial 27 finished with value: 1.7936875149607658 and parameters: {'n_layers': 4, 'n_units_layer_0': 107, 'n_units_layer_1': 198, 'n_units_layer_2': 26, 'n_units_layer_3': 27, 'dropout': 0.03734485961503834, 'weight_decay': 0.00039233088420413854, 'lr': 0.0004014094258827974}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:54:15,232] Trial 28 finished with value: 1.613228090107441 and parameters: {'n_layers': 4, 'n_units_layer_0': 158, 'n_units_layer_1': 117, 'n_units_layer_2': 59, 'n_units_layer_3': 93, 'dropout': 0.08774424911140818, 'weight_decay': 3.640742890277112e-05, 'lr': 0.0006825574422950866}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:54:56,828] Trial 29 finished with value: 1.2404045462608337 and parameters: {'n_layers': 5, 'n_units_layer_0': 177, 'n_units_layer_1': 212, 'n_units_layer_2': 31, 'n_units_layer_3': 39, 'n_units_layer_4': 211, 'dropout': 0.005314652140272255, 'weight_decay': 0.00012317033028720235, 'lr': 0.0010604017688530904}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:55:24,140] Trial 30 finished with value: 1.41347885876894 and parameters: {'n_layers': 6, 'n_units_layer_0': 170, 'n_units_layer_1': 212, 'n_units_layer_2': 52, 'n_units_layer_3': 37, 'n_units_layer_4': 253, 'n_units_layer_5': 233, 'dropout': 0.0076285127515628715, 'weight_decay': 0.00010859040478679842, 'lr': 0.001037448712845061}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:56:16,446] Trial 31 finished with value: 1.201463095843792 and parameters: {'n_layers': 6, 'n_units_layer_0': 159, 'n_units_layer_1': 209, 'n_units_layer_2': 57, 'n_units_layer_3': 39, 'n_units_layer_4': 252, 'n_units_layer_5': 204, 'dropout': 0.0003646078748754146, 'weight_decay': 0.00010530027746587731, 'lr': 0.000960635336266585}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:56:24,198] Trial 32 pruned.
[I 2025-11-23 02:57:27,681] Trial 33 finished with value: 1.197617083787918 and parameters: {'n_layers': 5, 'n_units_layer_0': 95, 'n_units_layer_1': 255, 'n_units_layer_2': 52, 'n_units_layer_3': 31, 'n_units_layer_4': 109, 'dropout': 0.002520957796829966, 'weight_decay': 1.238894890478252e-05, 'lr': 0.0010442970047793963}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:58:12,809] Trial 34 finished with value: 1.360861949622631 and parameters: {'n_layers': 5, 'n_units_layer_0': 97, 'n_units_layer_1': 135, 'n_units_layer_2': 112, 'n_units_layer_3': 38, 'n_units_layer_4': 119, 'dropout': 0.00948068184535328, 'weight_decay': 9.607130785421909e-06, 'lr': 0.0014530054147628463}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 02:58:16,803] Trial 35 pruned.
[I 2025-11-23 02:58:21,021] Trial 36 pruned.
[I 2025-11-23 02:58:28,455] Trial 37 pruned.
[I 2025-11-23 02:58:36,393] Trial 38 pruned.
[I 2025-11-23 02:58:43,558] Trial 39 pruned.
[I 2025-11-23 02:59:06,176] Trial 40 pruned.
[I 2025-11-23 02:59:10,065] Trial 41 pruned.
[I 2025-11-23 02:59:13,960] Trial 42 pruned.
[I 2025-11-23 02:59:17,806] Trial 43 pruned.
[I 2025-11-23 02:59:40,283] Trial 44 pruned.
[I 2025-11-23 02:59:43,754] Trial 45 pruned.
[I 2025-11-23 03:00:00,520] Trial 46 pruned.
[I 2025-11-23 03:00:53,184] Trial 47 finished with value: 1.1852517761290073 and parameters: {'n_layers': 4, 'n_units_layer_0': 88, 'n_units_layer_1': 219, 'n_units_layer_2': 55, 'n_units_layer_3': 107, 'dropout': 0.00069481940927138, 'weight_decay': 0.0005071762006108344, 'lr': 0.0002463990159787332}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 03:00:56,639] Trial 48 pruned.
[I 2025-11-23 03:01:41,484] Trial 49 finished with value: 1.4366165325045586 and parameters: {'n_layers': 5, 'n_units_layer_0': 83, 'n_units_layer_1': 213, 'n_units_layer_2': 101, 'n_units_layer_3': 47, 'n_units_layer_4': 53, 'dropout': 0.018563215031454947, 'weight_decay': 0.0012629406377915899, 'lr': 0.0022565254138578856}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 03:01:45,353] Trial 50 pruned.
[I 2025-11-23 03:01:48,776] Trial 51 pruned.
[I 2025-11-23 03:01:55,117] Trial 52 pruned.
[I 2025-11-23 03:02:11,741] Trial 53 pruned.
[I 2025-11-23 03:02:15,992] Trial 54 pruned.
[I 2025-11-23 03:02:19,861] Trial 55 pruned.
[I 2025-11-23 03:02:23,357] Trial 56 pruned.
[I 2025-11-23 03:02:27,224] Trial 57 pruned.
[I 2025-11-23 03:02:34,019] Trial 58 pruned.
[I 2025-11-23 03:02:37,443] Trial 59 pruned.
[I 2025-11-23 03:02:41,277] Trial 60 pruned.
[I 2025-11-23 03:03:02,174] Trial 61 pruned.
[I 2025-11-23 03:03:06,372] Trial 62 pruned.
[I 2025-11-23 03:03:10,393] Trial 63 pruned.
[I 2025-11-23 03:03:14,779] Trial 64 pruned.
[I 2025-11-23 03:03:46,045] Trial 65 finished with value: 1.4443611428141594 and parameters: {'n_layers': 5, 'n_units_layer_0': 144, 'n_units_layer_1': 203, 'n_units_layer_2': 72, 'n_units_layer_3': 58, 'n_units_layer_4': 255, 'dropout': 0.015149354017342995, 'weight_decay': 3.7772570951906723e-06, 'lr': 0.0007278014556843749}. Best is trial 25 with value: 1.1774947792291641.
[I 2025-11-23 03:03:52,548] Trial 66 pruned.
[I 2025-11-23 03:03:56,874] Trial 67 pruned.
[I 2025-11-23 03:04:03,265] Trial 68 pruned.
[I 2025-11-23 03:04:06,346] Trial 69 pruned.
[I 2025-11-23 03:04:10,654] Trial 70 pruned.
[I 2025-11-23 03:04:18,475] Trial 71 pruned.
[I 2025-11-23 03:05:09,131] Trial 72 finished with value: 1.1382151767611504 and parameters: {'n_layers': 6, 'n_units_layer_0': 111, 'n_units_layer_1': 194, 'n_units_layer_2': 43, 'n_units_layer_3': 38, 'n_units_layer_4': 209, 'n_units_layer_5': 148, 'dropout': 0.00014918404137771214, 'weight_decay': 0.00014905195530893345, 'lr': 0.0010313311540572718}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:05:31,851] Trial 73 pruned.
[I 2025-11-23 03:05:39,550] Trial 74 pruned.
[I 2025-11-23 03:06:13,225] Trial 75 finished with value: 1.270216278731823 and parameters: {'n_layers': 6, 'n_units_layer_0': 226, 'n_units_layer_1': 153, 'n_units_layer_2': 42, 'n_units_layer_3': 64, 'n_units_layer_4': 31, 'n_units_layer_5': 149, 'dropout': 0.00024684887807674763, 'weight_decay': 5.2690036884027915e-05, 'lr': 0.0009785336141515824}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:06:17,590] Trial 76 pruned.
[I 2025-11-23 03:06:25,828] Trial 77 pruned.
[I 2025-11-23 03:06:53,909] Trial 78 finished with value: 1.2855982296168804 and parameters: {'n_layers': 6, 'n_units_layer_0': 149, 'n_units_layer_1': 176, 'n_units_layer_2': 63, 'n_units_layer_3': 80, 'n_units_layer_4': 14, 'n_units_layer_5': 171, 'dropout': 0.0003655629264687811, 'weight_decay': 0.00017769461279185038, 'lr': 0.0009999830737947334}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:07:26,464] Trial 79 finished with value: 1.368452362716198 and parameters: {'n_layers': 6, 'n_units_layer_0': 157, 'n_units_layer_1': 97, 'n_units_layer_2': 68, 'n_units_layer_3': 85, 'n_units_layer_4': 10, 'n_units_layer_5': 167, 'dropout': 0.011682101862342153, 'weight_decay': 0.00017253018168384023, 'lr': 0.0009564637409667802}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:07:31,133] Trial 80 pruned.
[I 2025-11-23 03:07:53,699] Trial 81 pruned.
[I 2025-11-23 03:08:20,494] Trial 82 finished with value: 1.5583667308092117 and parameters: {'n_layers': 6, 'n_units_layer_0': 238, 'n_units_layer_1': 175, 'n_units_layer_2': 54, 'n_units_layer_3': 70, 'n_units_layer_4': 32, 'n_units_layer_5': 143, 'dropout': 0.015328046080058813, 'weight_decay': 0.00011523061599396723, 'lr': 0.0011898909859175712}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:08:43,052] Trial 83 pruned.
[I 2025-11-23 03:09:37,453] Trial 84 finished with value: 1.157666403800249 and parameters: {'n_layers': 6, 'n_units_layer_0': 175, 'n_units_layer_1': 207, 'n_units_layer_2': 36, 'n_units_layer_3': 51, 'n_units_layer_4': 16, 'n_units_layer_5': 185, 'dropout': 0.0006363124239062606, 'weight_decay': 0.0010018339937011536, 'lr': 0.0007519427021726063}. Best is trial 72 with value: 1.1382151767611504.
[I 2025-11-23 03:09:45,689] Trial 85 pruned.
[I 2025-11-23 03:09:50,016] Trial 86 pruned.
[I 2025-11-23 03:09:54,674] Trial 87 pruned.
[I 2025-11-23 03:10:17,443] Trial 88 pruned.
[I 2025-11-23 03:10:21,689] Trial 89 pruned.
[I 2025-11-23 03:10:26,222] Trial 90 pruned.
[I 2025-11-23 03:10:30,723] Trial 91 pruned.
[I 2025-11-23 03:10:35,018] Trial 92 pruned.
[I 2025-11-23 03:10:38,376] Trial 93 pruned.
[I 2025-11-23 03:10:42,061] Trial 94 pruned.
[I 2025-11-23 03:10:50,074] Trial 95 pruned.
[I 2025-11-23 03:10:53,766] Trial 96 pruned.
[I 2025-11-23 03:10:58,024] Trial 97 pruned.
[I 2025-11-23 03:11:02,246] Trial 98 pruned.
[I 2025-11-23 03:11:05,810] Trial 99 pruned.
Melhores hiperparâmetros:
{'n_layers': 6, 'n_units_layer_0': 111, 'n_units_layer_1': 194, 'n_units_layer_2': 43, 'n_units_layer_3': 38, 'n_units_layer_4': 209, 'n_units_layer_5': 148, 'dropout': 0.00014918404137771214, 'weight_decay': 0.00014905195530893345, 'lr': 0.0010313311540572718}Loop para treinar a rede com o melhor conjunto de hiperparâmetros
def train_and_eval(model, optimizer, criterion, train_loader=train_loader, val_loader=val_loader, n_epochs=qtd_epocas):
for epoch in range(n_epochs):
model.train()
for xb, yb in train_loader:
optimizer.zero_grad()
pred = model(xb)
loss = criterion(pred, yb)
loss.backward()
optimizer.step()
model.eval()
val_losses = []
with torch.no_grad():
for xb, yb in val_loader:
pred = model(xb)
val_losses.append(criterion(pred, yb).item())
return print(f"MSE no conjunto de validação: {np.mean(val_losses):.6f}")Re-treinando o modelo final com os melhores hiperparâmetros
best_params = study.best_trial.params
hidden = [best_params[f"n_units_layer_{i}"] for i in range(best_params["n_layers"])]
best_model = build_model(
input_dim=x_treino.shape[0],
hidden_layers=hidden,
activation_name="relu",
dropout=best_params["dropout"]
)
optimizer = optim.Adam(
best_model.parameters(),
lr=best_params["lr"],
weight_decay=best_params["weight_decay"]
)
criterion = nn.MSELoss()
train_and_eval(best_model, optimizer, criterion)MSE no conjunto de validação: 1.290015Avaliação final no conjunto de teste
best_model.eval()
test_losses = []
with torch.no_grad():
for xb, yb in test_loader:
pred = best_model(xb)
test_losses.append(((pred - yb)**2).mean().item())
final_test_mse = np.mean(test_losses)
print(f"MSE no conjunto de teste: {final_test_mse:.6f}")MSE no conjunto de teste: 1.442020best_model.eval()
y_true = []
y_pred = []
with torch.no_grad():
for xb, yb in test_loader:
preds = best_model(xb)
y_true.extend(yb.cpu().numpy().flatten())
y_pred.extend(preds.cpu().numpy().flatten())df_plot = pd.DataFrame({
"y_true": y_true,
"y_pred": y_pred
})plt.figure(figsize=(6,6))
sns.scatterplot(x="y_true", y="y_pred", data=df_plot)
lims = [
min(df_plot.y_true.min(), df_plot.y_pred.min()),
max(df_plot.y_true.max(), df_plot.y_pred.max())
]
plt.plot(lims, lims, "--", linewidth=2)
plt.xlabel("Valor observado (yᵢ)")
plt.ylabel("Valor previsto (ŷᵢ)")
plt.title("Valores observados vs. previstos no conjunto de teste")
plt.grid(True)
plt.show()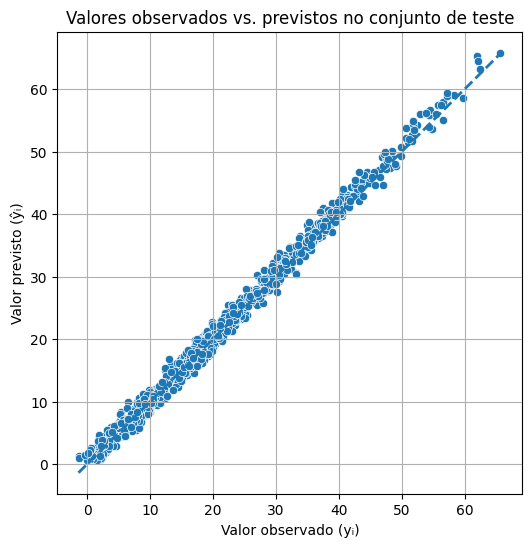
Na lista anterior, o gráfico de valores observados vs previstos apresentava sérias limitações e imperfeições em relação a linha de 45 graus esperada. Existia um limite inferior e superior que as predições não conseguiam ultrapassar. Desta vez, a rede praticamente crava com os verdadeiros valores.
best_model.eval()
x_input = torch.tensor([[1.0, 1.0]], dtype=torch.float32).to(device)
with torch.no_grad():
y_pred = best_model(x_input)
print("Predição para (x1=1, x2=1):", y_pred.item())Predição para (x1=1, x2=1): 14.711983680725098Note: O valor analítico neste caso seria \(Y \sim N(\mu,1)\), onde \(\mu= |1^3 - 30*sin(1) + 10| \approx 14,24413\). Pode-se dizer que a rede cravou!
n = 100
x1_lin = np.linspace(-3, 3, n)
x2_lin = np.linspace(-3, 3, n)
X1g, X2g = np.meshgrid(x1_lin, x2_lin)
Y_true = np.abs(X1g**3 - 30*np.sin(X2g) + 10)
grid_points = np.column_stack([X1g.ravel(), X2g.ravel()])
grid_tensor = torch.tensor(grid_points, dtype=torch.float32).to(device)
best_model.eval()
with torch.no_grad():
y_grid_pred = best_model(grid_tensor).cpu().numpy().flatten()
Y_pred = y_grid_pred.reshape(n, n)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
im0 = axes[0].imshow(
Y_true,
extent=[-3, 3, -3, 3],
origin="lower",
cmap="viridis",
aspect="auto"
)
axes[0].set_title("Superfície verdadeira (processo gerador)")
axes[0].set_xlabel("X1")
axes[0].set_ylabel("X2")
fig.colorbar(im0, ax=axes[0], shrink=0.8)
im1 = axes[1].imshow(
Y_pred,
extent=[-3, 3, -3, 3],
origin="lower",
cmap="viridis",
aspect="auto"
)
axes[1].set_title("Superfície estimada pela rede neural")
axes[1].set_xlabel("X1")
axes[1].set_ylabel("X2")
fig.colorbar(im1, ax=axes[1], shrink=0.8)
plt.tight_layout()
plt.show()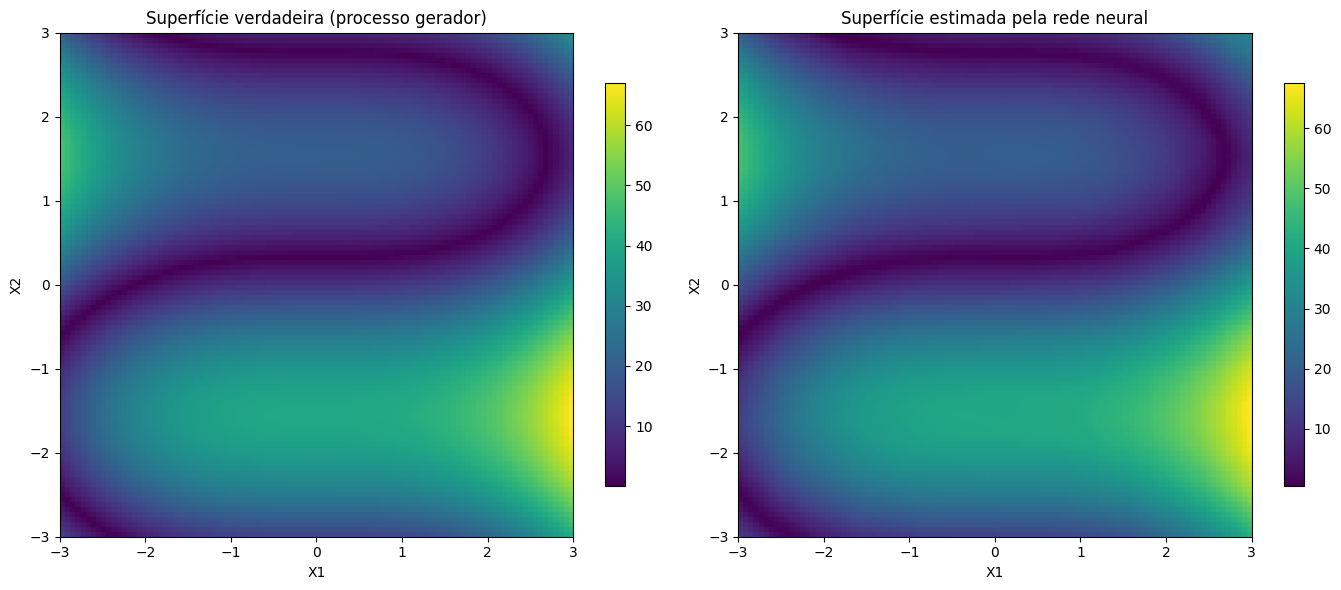
Pela comparação visual dos gráficos, pode-se observar que a rede praticamente aprendeu o processo gerador, sendo até difícil apontar, sem a legenda, qual o gráfico do processo gerador e qual o gráfico dos valores estimados pela rede
best_model.eval()
val_losses = []
criterion = nn.MSELoss()
X_test_list = []
y_test_list = []
for xb, yb in test_loader:
X_test_list.append(xb)
y_test_list.append(yb)
X_test_t = torch.cat(X_test_list, dim=0)
y_test_t = torch.cat(y_test_list, dim=0)
with torch.no_grad():
for xb, yb in val_loader:
pred = best_model(xb)
loss = criterion(pred, yb)
val_losses.append(loss.item())
val_mse = np.mean(val_losses)
sigma_hat = np.sqrt(val_mse)
with torch.no_grad():
y_pred_test = best_model(X_test_t).cpu().numpy().flatten()
y_true_test = y_test_t.cpu().numpy().flatten()
x1_test = X_test_t[:, 0].cpu().numpy()
x2_test = X_test_t[:, 1].cpu().numpy()
lower = y_pred_test - 1.96 * sigma_hat
upper = y_pred_test + 1.96 * sigma_hat
captured = (y_true_test >= lower) & (y_true_test <= upper)
plt.figure(figsize=(8, 7))
plt.scatter(
x1_test,
x2_test,
c=np.where(captured, "green", "red"),
s=12
)
plt.xlabel("x1.obs")
plt.ylabel("x2.obs")
plt.title("Pontos do conjunto de teste cobertos pelo IC de 95%")
plt.show()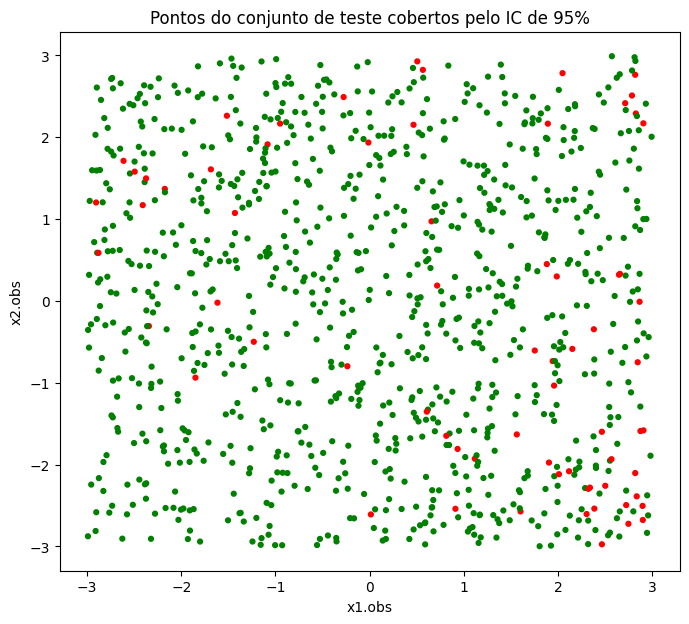
Desta vez, não temos mais problemas de ajuste local como no modelo linear da lista anterior. Lá, o modelo, mesmo com um intervalo de confiança gigantesco, não conseguia capturar os valores nas regiões em que os verdadeiros valores eram mais extremos.
Note:
sigma_hat*1.96np.float64(2.226144950591428)Ou seja, o intervalo de confiança 95% da rede é minúsculo, e ainda assim consegue capturar praticamente todos os valores, com os residuais sem nenhum padrão aparente de falta de ajuste local.
X1_train = x_treino[[0], :]
X1_val = x_val[[0], :]
X1_test = x_teste[[0], :]
train_loader_x1, val_loader_x1, test_loader_x1 = make_loaders(
X1_train, y_treino,
X1_val, y_val,
X1_test, y_teste,
device
)
study_x1 = optuna.create_study(direction="minimize")
study_x1.optimize(lambda trial:
objective(trial, train_loader_x1, val_loader_x1, input_dim=X1_train.shape[0]),
n_trials=n_optuna
)X2_train = x_treino[[1], :]
X2_val = x_val[[1], :]
X2_test = x_teste[[1], :]
train_loader_x2, val_loader_x2, test_loader_x2 = make_loaders(
X2_train, y_treino,
X2_val, y_val,
X2_test, y_teste,
device
)
study_x2 = optuna.create_study(direction="minimize")
study_x2.optimize(lambda trial:
objective(trial, train_loader_x2, val_loader_x2, input_dim=X2_train.shape[0]),
n_trials=n_optuna
)def build_hidden_list(best_params):
n_layers = best_params["n_layers"]
return [best_params[f"n_units_layer_{i}"] for i in range(n_layers)]
def train_final_univariate_model(study, train_loader, val_loader, n_epochs=qtd_epocas):
best_params = study.best_trial.params
hidden_list = build_hidden_list(best_params)
model = build_model(
input_dim=1,
hidden_layers=hidden_list,
activation_name="relu",
dropout=best_params["dropout"]
)
optimizer = optim.Adam(
model.parameters(),
lr=best_params["lr"],
weight_decay=best_params["weight_decay"]
)
criterion = nn.MSELoss()
train_and_eval(
model,
optimizer,
criterion,
train_loader=train_loader,
val_loader=val_loader,
n_epochs=n_epochs
)
return modelmodel_x1 = train_final_univariate_model(
study_x1,
train_loader_x1,
val_loader_x1
)
model_x2 = train_final_univariate_model(
study_x2,
train_loader_x2,
val_loader_x2
)MSE no conjunto de validação: 178.645797
MSE no conjunto de validação: 85.867234def mse_model(model, test_loader):
model.eval()
losses = []
with torch.no_grad():
for xb, yb in test_loader:
pred = model(xb)
losses.append(((pred - yb)**2).mean().item())
return np.mean(losses)
mse_x1 = mse_model(model_x1, test_loader_x1)
mse_x2 = mse_model(model_x2, test_loader_x2)
print("MSE usando somente x1:", mse_x1)
print("MSE usando somente x2:", mse_x2)MSE usando somente x1: 180.3589630126953
MSE usando somente x2: 82.07731461524963def permutation_importance(model, X_test, y_test, idx_feature, n_repeats=10):
base_X = X_test.clone()
model.eval()
with torch.no_grad():
base_pred = model(base_X).cpu().numpy().flatten()
base_mse = np.mean((base_pred - y_test.cpu().numpy().flatten())**2)
deltas = []
for _ in range(n_repeats):
Xp = base_X.clone()
perm = torch.randperm(Xp.shape[0])
Xp[:, idx_feature] = Xp[perm, idx_feature]
with torch.no_grad():
pred = model(Xp).cpu().numpy().flatten()
mse_perm = np.mean((pred - y_test.cpu().numpy().flatten())**2)
deltas.append(mse_perm - base_mse)
return np.mean(deltas), np.std(deltas)delta_x1 = permutation_importance(best_model, X_test_t, y_test_t, idx_feature=0)
delta_x2 = permutation_importance(best_model, X_test_t, y_test_t, idx_feature=1)
delta_x1_mean = float(delta_x1[0])
delta_x2_mean = float(delta_x2[0])
print(f"x1: ΔMSE = {delta_x1_mean:.3f}")
print(f"x2: ΔMSE = {delta_x2_mean:.3f}")x1: ΔMSE = 164.100
x2: ΔMSE = 359.123Conclusão: x2 é mais importante que x1 para o modelo, visto que embaralhar x2 causa uma piora bem maior no desempenho do que embaralhar x1.
Se lembrarmos o nosso processo gerador:
\[\begin{align*} Y & \sim N(\mu, \sigma^2=1) \\ \mu & = |X_1^3 - 30 \text{sen} (X_2) + 10| \\ X_j & \sim \text{Uniforme}(-3, 3), \quad j=1, 2. \end{align*}\]
Temos então que a parcela que depende de x1 pode ser até \(3^3=27\), enquanto a parcela que depende de x2 pode ser até \(30*sen(x_2)=30\), se \(x=\frac{\pi}{2}\), por exemplo. Além disso, x2 carrega a informação senoidal do processo, o que é muito relavante para entender o padrão de variação de y.
def gather_from_loader(loader):
Xs, ys = [], []
for xb, yb in loader:
Xs.append(xb)
ys.append(yb)
if len(Xs)==0:
return None, None
X = torch.cat(Xs, dim=0)
y = torch.cat(ys, dim=0)
return X, y
def predict_on_tensor(model, X_tensor, batch_size=4096):
model.eval()
preds = []
with torch.no_grad():
n = X_tensor.shape[0]
for i in range(0, n, batch_size):
xb = X_tensor[i:i+batch_size].to(device)
p = model(xb).cpu()
preds.append(p)
return torch.cat(preds, dim=0)
def count_params(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)try:
X_train_t, y_train_t = gather_from_loader(train_loader)
X_val_t, y_val_t = gather_from_loader(val_loader)
X_test_t, y_test_t = gather_from_loader(test_loader)
except Exception:
X_train_t = torch.tensor(x_treino.T, dtype=torch.float32).to(device)
y_train_t = torch.tensor(y_treino.T, dtype=torch.float32).view(-1,1).to(device)
X_val_t = torch.tensor(x_val.T, dtype=torch.float32).to(device)
y_val_t = torch.tensor(y_val.T, dtype=torch.float32).view(-1,1).to(device)
X_test_t = torch.tensor(x_teste.T, dtype=torch.float32).to(device)
y_test_t = torch.tensor(y_teste.T, dtype=torch.float32).view(-1,1).to(device)best_model.eval()
with torch.no_grad():
teacher_test_pred = predict_on_tensor(best_model, X_test_t).cpu().numpy().ravel()
baseline_test_mse = float(np.mean((teacher_test_pred - y_test_t.cpu().numpy().ravel())**2))with torch.no_grad():
y_teacher_train = predict_on_tensor(best_model, X_train_t).cpu()
y_teacher_val = predict_on_tensor(best_model, X_val_t).cpu()
train_ds_student = TensorDataset(X_train_t.cpu(), y_teacher_train)
val_ds_student = TensorDataset(X_val_t.cpu(), y_teacher_val)def build_student(input_dim, hidden_layers, dropout=0.0, activation='relu'):
acts = {'relu': nn.ReLU(), 'sigmoid': nn.Sigmoid(), 'linear': nn.Identity()}
layers = []
prev = input_dim
for h in hidden_layers:
layers.append(nn.Linear(prev, h))
layers.append(copy.deepcopy(acts[activation]))
if dropout>0:
layers.append(nn.Dropout(dropout))
prev = h
layers.append(nn.Linear(prev, 1))
return nn.Sequential(*layers).to(device)def train_student(model, train_ds, val_ds, lr=learning_rate, weight_decay=1e-6,
batch_size=64, n_epochs=qtd_epocas, patience=paciencia, verbose=False):
opt = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = nn.MSELoss()
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=256, shuffle=False)
best_val = float("inf"); best_state = None; patience_count = 0
for epoch in range(n_epochs):
model.train()
for xb, yb in train_loader:
xb = xb.to(device); yb = yb.to(device)
opt.zero_grad()
out = model(xb)
loss = loss_fn(out, yb.to(device))
loss.backward(); opt.step()
model.eval()
vals = []
with torch.no_grad():
for xb, yb in val_loader:
xb = xb.to(device); yb = yb.to(device)
vals.append(float(loss_fn(model(xb), yb)))
val_mse = float(np.mean(vals))
if val_mse < best_val - 1e-12:
best_val = val_mse
best_state = {k:v.cpu().clone() for k,v in model.state_dict().items()}
patience_count = 0
else:
patience_count += 1
if patience_count >= patience:
break
if best_state is not None:
model.load_state_dict(best_state)
return model, best_valcandidates = [
[],
[4],
[8],
[16],
[8,4],
[16,8],
[32],
](Aceita modelo com MSE até 10% superior que o modelo base)
tol = 0.10
results = []
for hid in candidates:
student = build_student(input_dim=X_train_t.shape[1], hidden_layers=hid, dropout=0.0)
student, val_mse_student = train_student(student, train_ds_student, val_ds_student,
lr=learning_rate, weight_decay=1e-6, n_epochs=qtd_epocas, patience=paciencia)
student.eval()
with torch.no_grad():
pred_student_test = predict_on_tensor(student, X_test_t).cpu().numpy().ravel()
test_mse_student = float(np.mean((pred_student_test - y_test_t.cpu().numpy().ravel())**2))
nparams = count_params(student)
results.append({
"hidden": hid,
"val_mse_student": val_mse_student,
"test_mse_student": test_mse_student,
"nparams": nparams
})Selecionando e ajustando o modelo parcimonioso
acceptable = [r for r in results if r["test_mse_student"] <= baseline_test_mse*(1+tol)]
if len(acceptable)>0:
chosen = sorted(acceptable, key=lambda r: (r["nparams"], r["test_mse_student"]))[0]
else:
chosen = sorted(results, key=lambda r: (abs(r["test_mse_student"]-baseline_test_mse), r["nparams"]))[0]
chosen_student = build_student(input_dim=X_train_t.shape[1], hidden_layers=chosen["hidden"], dropout=0.0).to(device)
chosen_student, _ = train_student(chosen_student, train_ds_student, val_ds_student,
lr=learning_rate, weight_decay=1e-6, n_epochs=qtd_epocas, patience=paciencia)Modelo escolhido:
with torch.no_grad():
final_student_pred = predict_on_tensor(chosen_student, X_test_t).cpu().numpy().ravel()
final_student_test_mse = float(np.mean((final_student_pred - y_test_t.cpu().numpy().ravel())**2))
print(f"camadas ocultas = {chosen['hidden']}, nparams = {chosen['nparams']}")
print(f"MSE do modelo parcimonioso = {final_student_test_mse:.6f}")
print(f"MSE do modelo base= {baseline_test_mse:.6f}")
print(f"Diferença relativa = {(final_student_test_mse/baseline_test_mse - 1)*100:.2f}%")camadas ocultas = [16, 8], nparams = 193
MSE do modelo parcimonioso = 5.841157
MSE do modelo base= 1.432445
Diferença relativa = 307.78%Treinar uma rede menor para mimetizar os resultados de uma rede maior e mais complexa pode ser útil para colocar modelos em produção em sistemas simples ou que o custo de implementação de uma rede complexa seja alta demais. Pode ser útil também para tentar interpretar ou auditar um modelo.